プロットの基礎#
chemotools.plotting モジュールは、分光データおよびケモメトリックモデルの可視化を、高速、直感的、かつ**出版レベル**にするために設計されています。 標準的なケモメトリックプロットを、冗長な matplotlib コードを書く代わりに、数行で生成できます。
警告
このプロットモジュールは実験的であり、現在も積極的に開発が進められています。API は将来のバージョンで変更される可能性があります。 フィードバックを歓迎します。問題や提案は次のリンクから報告してください: paucablop/chemotools#issues
なぜ専用のプロットが必要なのか#
高次元のスペクトルデータやケモメトリックモデルを可視化するには、繰り返し記述される冗長なプロットコードが必要になることが多くあります。 chemotools は次の機能を提供することでこれを簡素化します:
ドメイン特化プロット: スペクトル、スコア、ローディング、外れ値プロットをすぐに利用できます。
インタラクティブ探索:
show()メソッドにより即時フィードバックが得られます。出版品質: 論文にも適したクリーンで標準化されたデザイン。
設計理念#
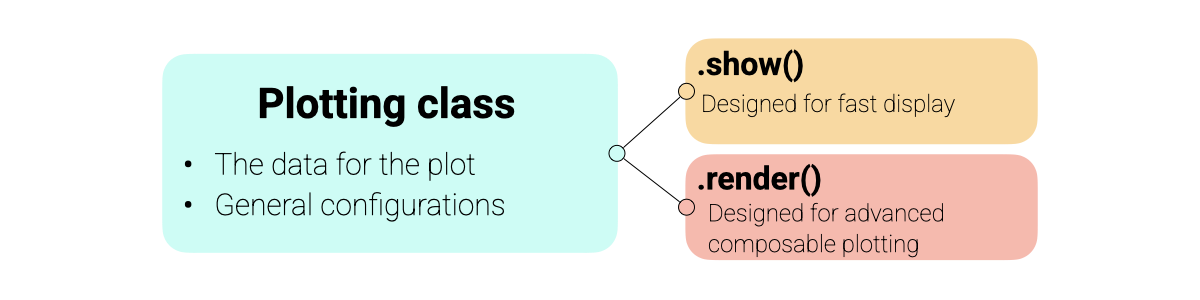
このプロットモジュールは、使いやすさと柔軟性のバランスを取るために設計された、一貫した 表示プロトコル を中心に構築されています。
オブジェクト指向: 各プロットタイプ(例:
SpectraPlot、ScoresPlot)はデータと設定を保持するクラスです。2 つの操作モード:
show(): 新しい図を即座に作成します。迅速な探索に最適です。render(ax): 既存の matplotlib 軸にプロットを描画します。高度なマルチパネル図やダッシュボードを作成するために設計されています。
matplotlib との統合: すべてのプロットは標準の
matplotlib.axes.Axesオブジェクトを返すため、 注釈・ライン・スタイルの追加などを、通常の matplotlib コマンドで行えます。
プロットアーキテクチャの概要は以下のとおりです:
注釈
chemotools のプロットは matplotlib 上に構築されているため、render() や show() が返すプロットを、 好みの matplotlib コマンドで自由にカスタマイズできます。
スペクトルの可視化#
SpectraPlot は探索的データ解析のための主要なツールであり、スペクトルデータを柔軟に可視化できます。
この例では、chemotools に含まれる発酵データセットを使用します。
from chemotools.datasets import load_fermentation_train
from chemotools.feature_selection import RangeCut
import numpy as np
# Load data
X, Y = load_fermentation_train()
wavenumbers = X.columns.values
y = Y["glucose"]
X = X.values
# Measuring date
measuring_date = np.array(["2023-01-01"] * 10 + ["2023-01-02"] * 11)
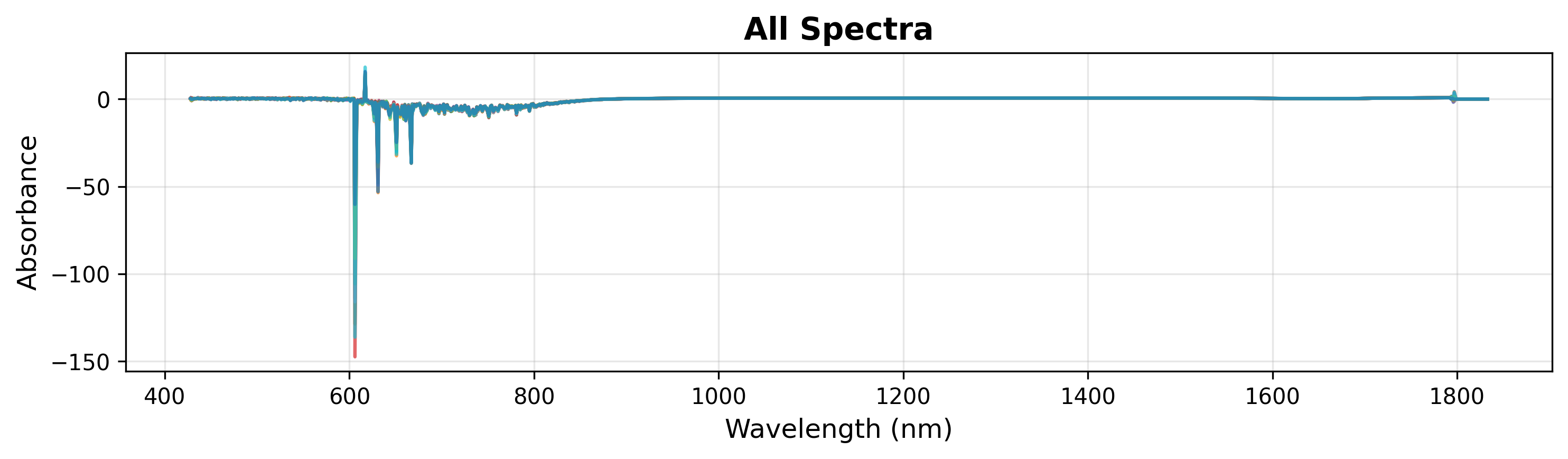
1. クイック可視化
データを素早く確認するには、波数とスペクトル行列を渡すだけです。すべてのスペクトルが単一の色でプロットされます。
# Create plot object
plot = SpectraPlot(x=wavenumbers, y=X)
# Display it
fig = plot.show(title="All Spectra", ylabel="Absorbance")
探索中に、スペクトルの特定領域を確認したい場合があります。これは show() メソッドで xlim を指定することで可能です(下記参照)。
# Display it
fig = plot.show(title="All Spectra", ylabel="Absorbance", xlim=(900, 1500))
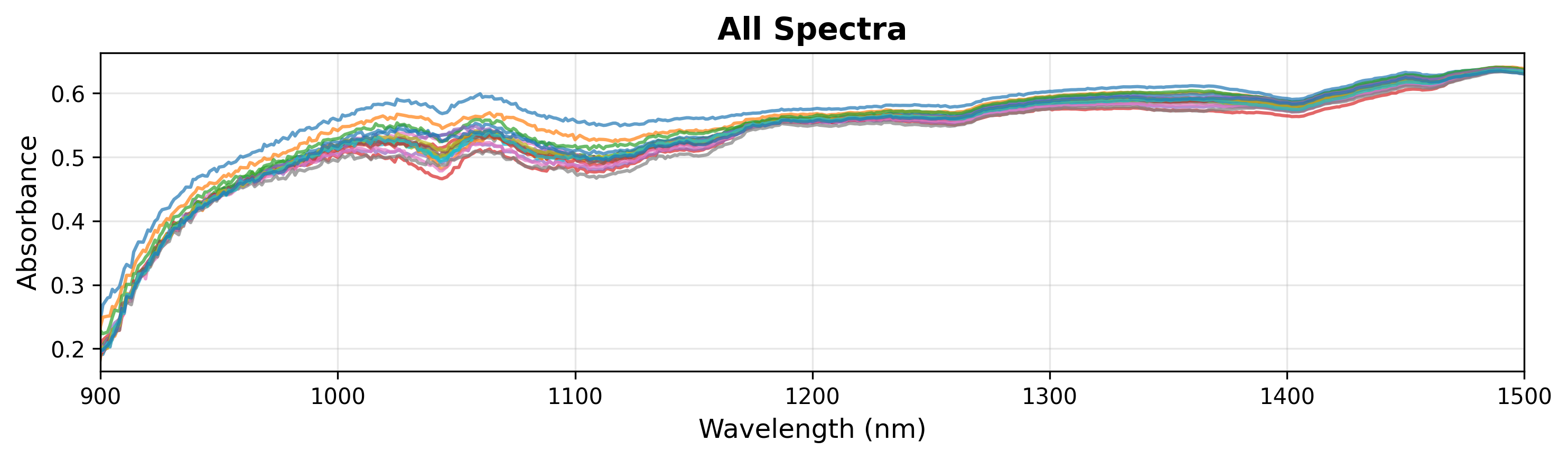
注釈
SpectraPlot はデータ範囲に基づいて y 軸スケールを自動調整します。特定の特徴に焦点を当てたい場合、ylim を手動で設定できます。
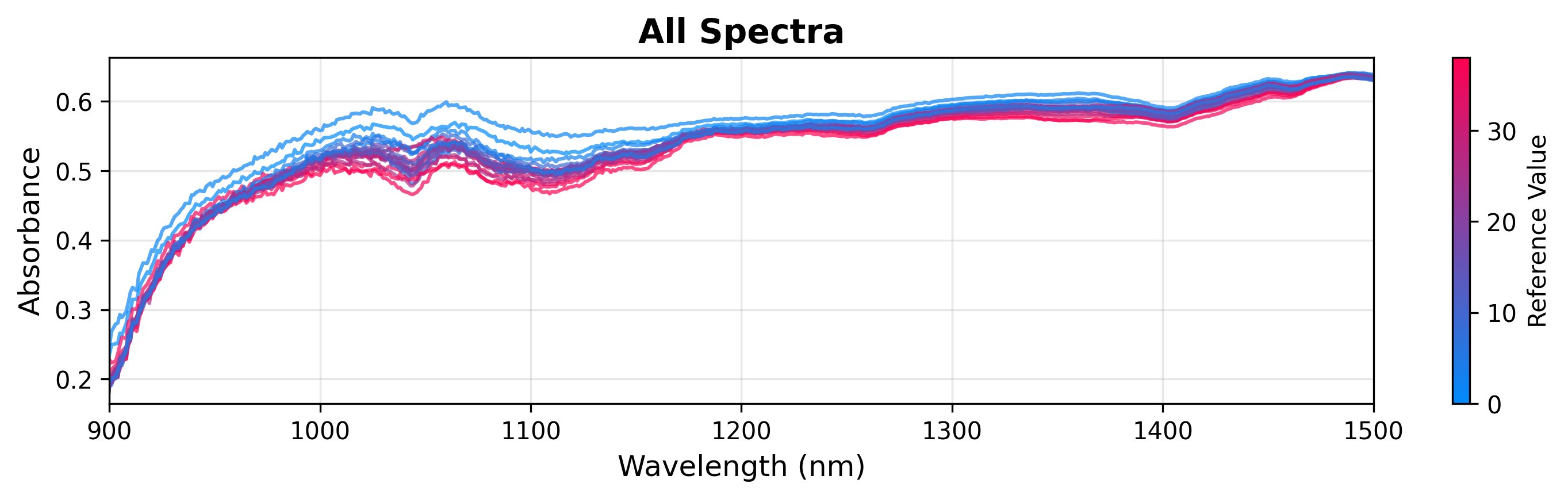
2. 連続変数による着色
連続ターゲット変数(例: グルコース濃度)に基づきスペクトルを着色し、相関を視覚化できます。
# Create plot object
plot = SpectraPlot(x=wavenumbers, y=X, color_by=y)
# Display it
fig = plot.show(title="All Spectra", ylabel="Absorbance", xlim=(900, 1500))
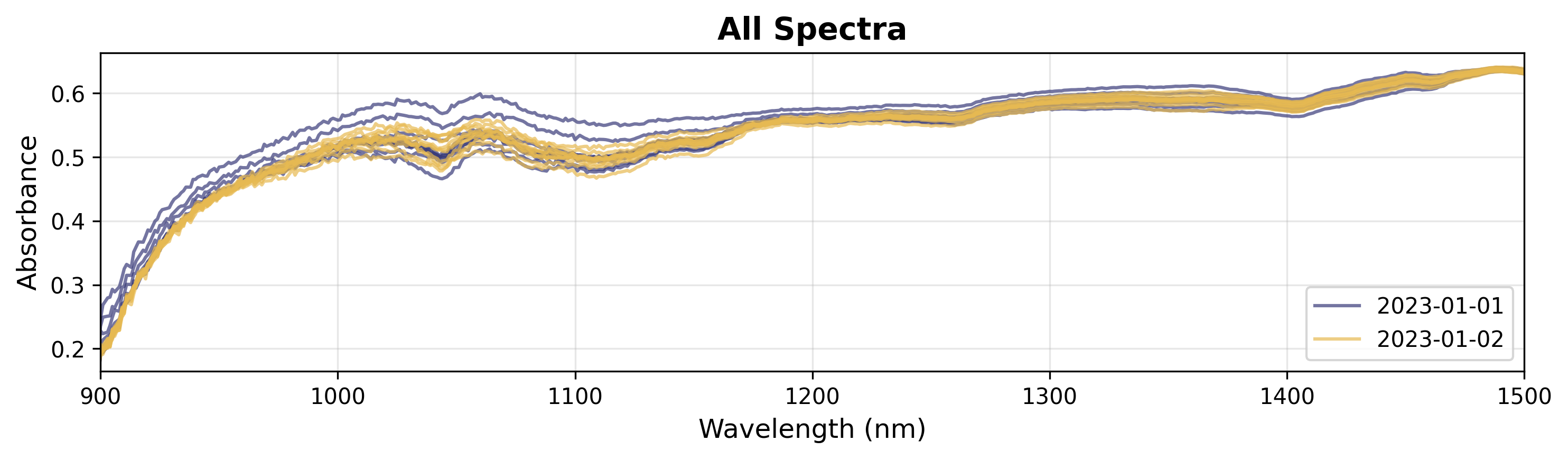
3. カテゴリ変数による着色
カテゴリデータ(例: バッチ、実験条件)がある場合、グループごとに着色できます。
# Create plot object
plot = SpectraPlot(x=wavenumbers, y=X, color_by=measuring_date, color_mode="categorical")
# Display it
fig = plot.show(title="All Spectra", ylabel="Absorbance", xlim=(900, 1500))
モデルの解析#
PCA や PLS のようなケモメトリックモデルを適合した後、その結果を可視化することは解釈に不可欠です。 このセクションでは、chemotools の発酵データを使用して適合した簡易 PCA モデルを使用します。
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Fit a PCA model
pca = PCA(n_components=3)
scores = pca.fit_transform(X)
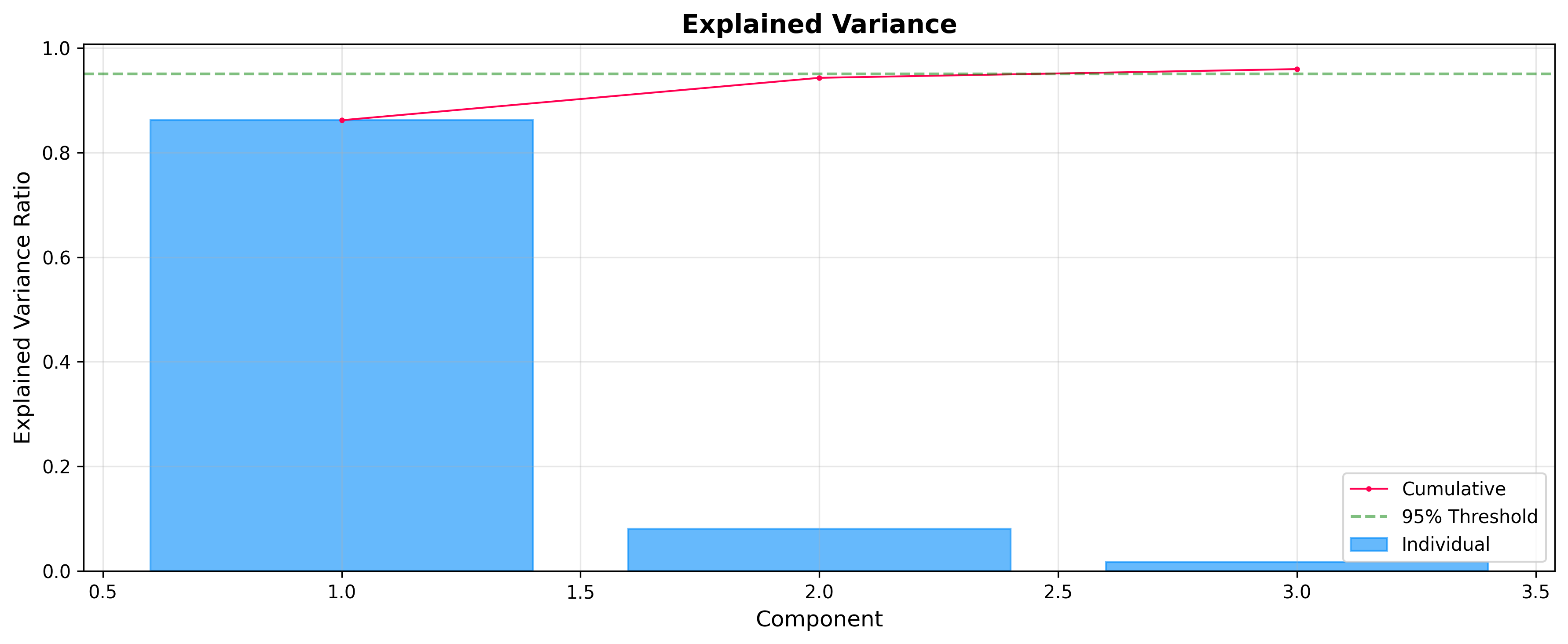
寄与率: コンポーネントの選択
スコアやローディングを解析する前に、各コンポーネントがどれだけの分散を説明するかを確認することが有用です。 ExplainedVariancePlot は最適なコンポーネント数を決定するのに役立ちます。
from chemotools.plotting import ExplainedVariancePlot
# Plot explained variance ratio
plot = ExplainedVariancePlot(pca.explained_variance_ratio_)
fig = plot.show(title="Explained Variance")
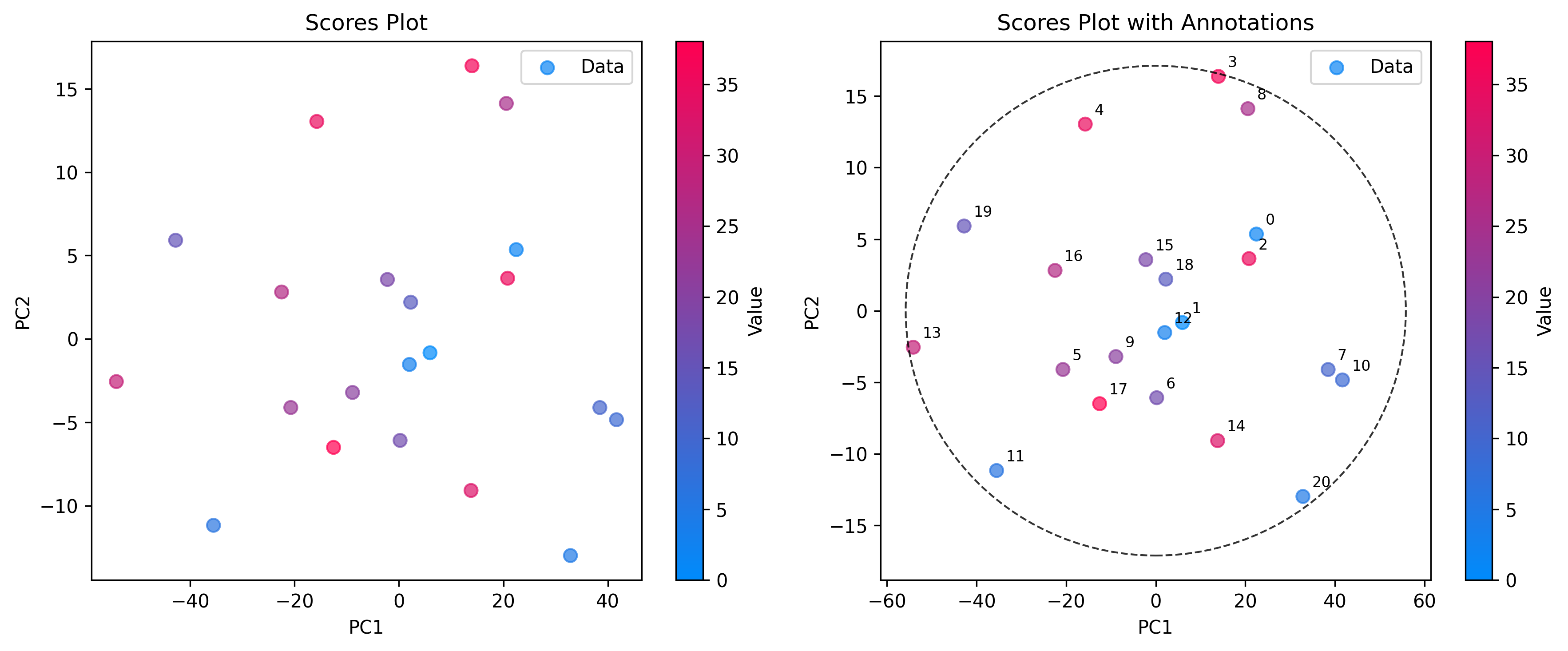
スコア: サンプル空間
ScoresPlot を使用すると、サンプル間の関係を視覚化できます。これはクラスタ、トレンド、外れ値を特定するために重要です。 ScoresPlot は非常に柔軟で、信頼楕円やサンプル注釈などモデルのさまざまな側面を示す複合図の作成にも利用できます。
from chemotools.plotting import ScoresPlot
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
# 1. Simple2D scores plot colored by glucose concentration
plot = ScoresPlot(scores, components=(0, 1), color_by=y)
plot.render(ax=ax[0])
ax[0].set_title("Scores Plot")
# 2. Advanced scores plot with confidence ellipse and annotations
sample_names = [f"{i}" for i in range(len(scores))]
plot = ScoresPlot(
scores,
confidence_ellipse=0.9,
annotations=sample_names,
components=(0, 1),
color_by=y,
)
plot.render(ax=ax[1])
ax[1].set_title("Scores Plot with Annotations")
注釈
2 つのプロットを 1 つの図にまとめるために、render(ax=...) メソッドを使用してそれぞれを特定の軸に描画しました。 これによりレイアウトやスタイルを正確に制御できます。
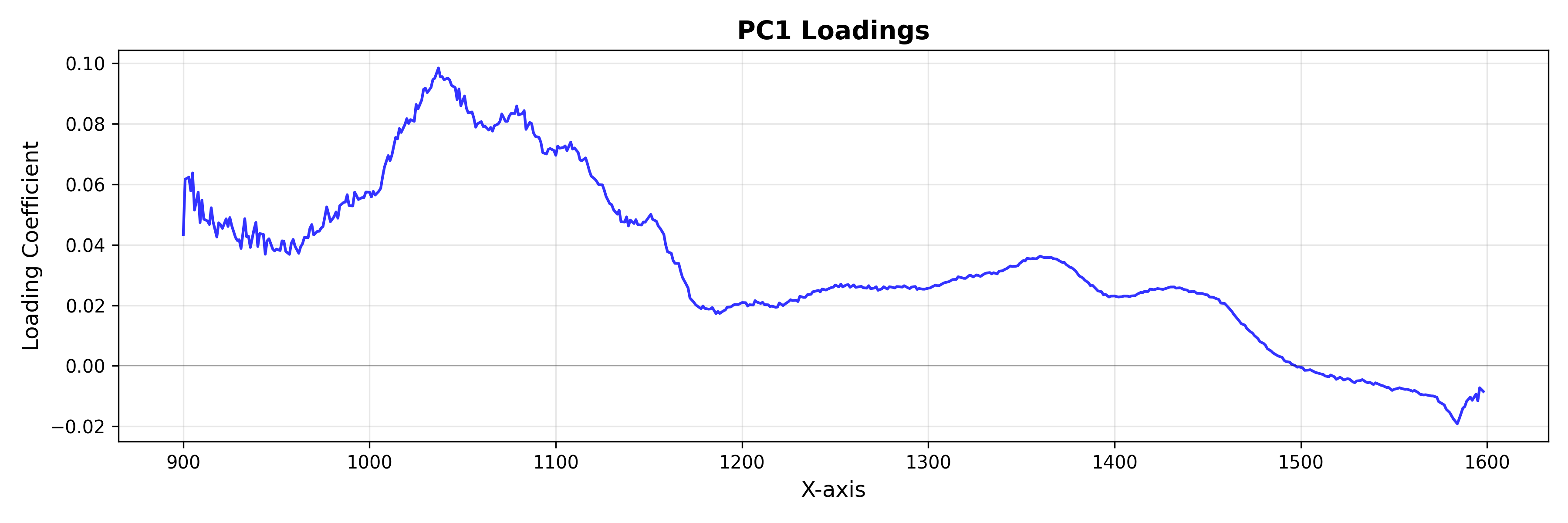
ローディング: 特徴空間
LoadingsPlot を使用すると、モデルに最も寄与するスペクトル特徴を理解できます。
from chemotools.plotting import LoadingsPlot
loadings = pca.components_.T
# Plot loadings for the first component
plot = LoadingsPlot(loadings, feature_names=wavenumbers, components=0)
fig = plot.show(title="PC1 Loadings", ylabel="Loading Coefficient")
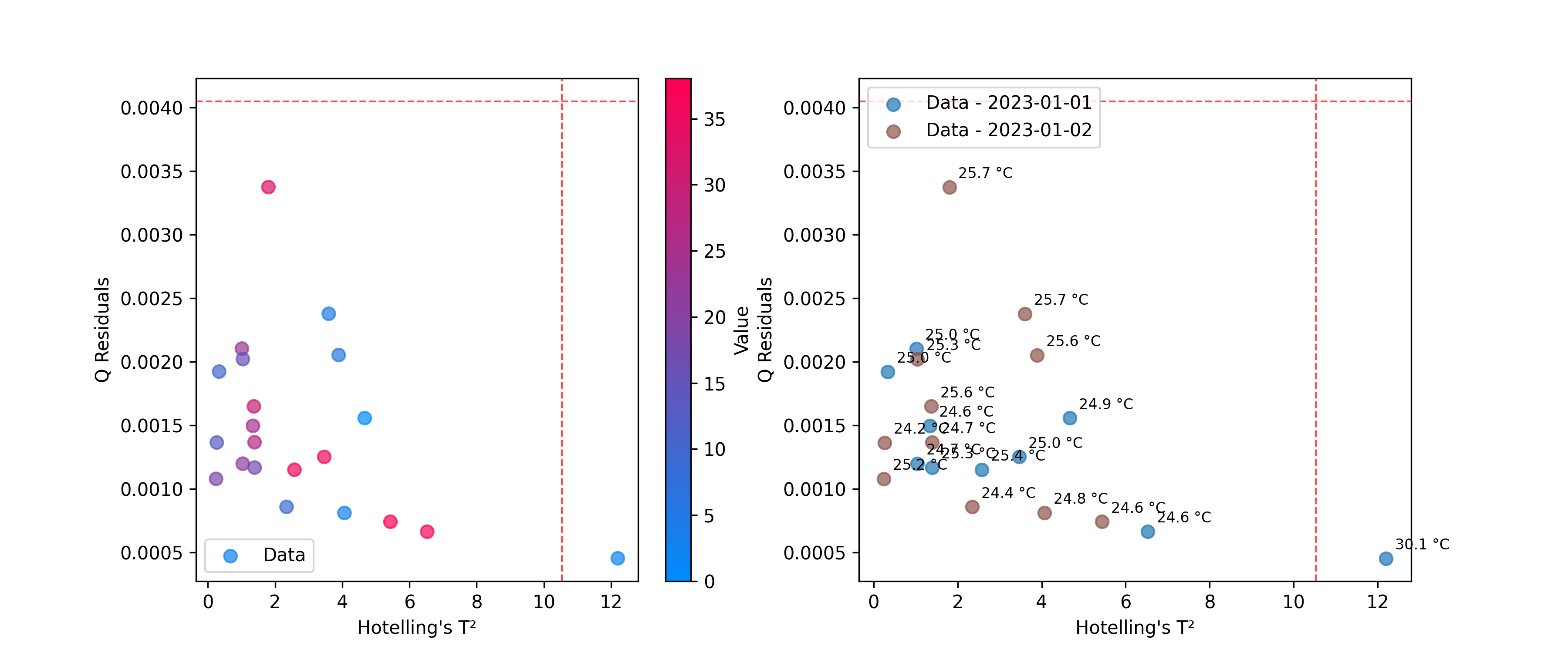
外れ値検出
Hotelling の T² や Q 残差などの指標を用いて、モデルに適合しないサンプルを特定するには DistancesPlot を使用します。 これらの統計量の計算方法については 外れ値 を参照してください。
from chemotools.outliers import HotellingT2, QResiduals
# Calculate outlier statistics
hotelling = HotellingT2(pca).fit(X)
q_residuals = QResiduals(pca).fit(X)
これで結果を可視化する準備が整いました。
from chemotools.plotting import DistancesPlot
# Plot T² vs Q-residuals
plot = DistancesPlot(
x=hotelling.predict_residuals(X_cut),
y=q_residuals.predict_residuals(X_cut),
confidence_lines=(hotelling.critical_value_, q_residuals.critical_value_),
color_by=y,
).render(ax=ax[0],xlabel="Hotelling's T²", ylabel="Q Residuals")
plot = DistancesPlot(
x=hotelling.predict_residuals(X_cut),
y=q_residuals.predict_residuals(X_cut),
confidence_lines=(hotelling.critical_value_, q_residuals.critical_value_),
color_by=measuring_date,
annotations=temperatures,
).render(ax=ax[1],xlabel="Hotelling's T²", ylabel="Q Residuals")
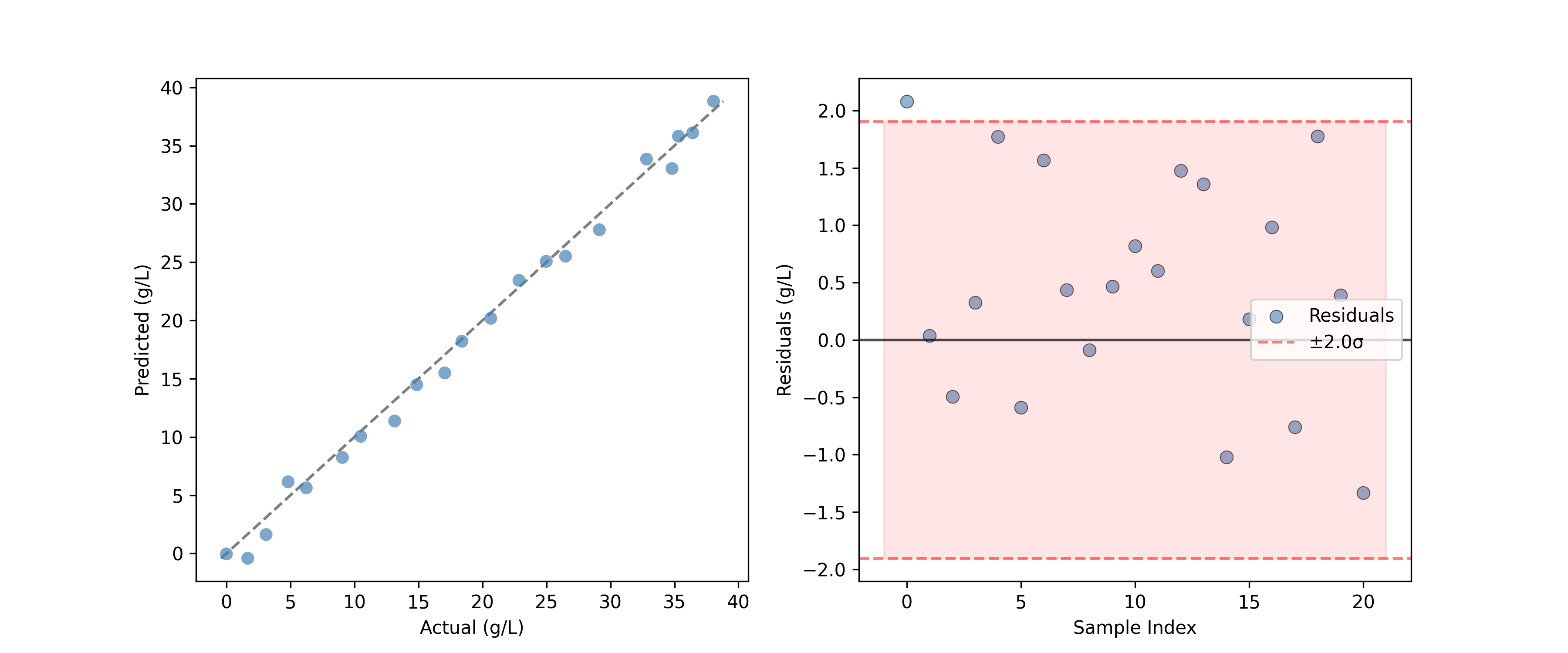
予測の評価#
回帰モデルでは、PredictedVsActualPlot がモデル性能を評価する標準的な手段となります。
from chemotools.plotting import PredictedVsActualPlot, YResidualsPlot
y_residuals = y_test - y_pred
# Assume y_pred comes from a PLS model
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
PredictedVsActualPlot(y_true=y_test, y_pred=y_pred).render(
ax=ax[0], xlabel="Actual (g/L)", ylabel="Predicted (g/L)"
)
YResidualsPlot(residuals=y_residuals, add_confidence_band=True).render(
ax=ax[1], xlabel="Sample Index", ylabel="Residuals (g/L)"
)
複合図の作成#
すべてのプロットクラスは render(ax=...) メソッドをサポートしており、既存の matplotlib 軸にプロットを配置できます。 これはダッシュボードや比較図の作成に非常に有用です。
import matplotlib.pyplot as plt
# Create a figure with 2 subplots
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# Plot 1: All spectra
SpectraPlot(x=wavenumbers, y=X, color='lightgray').render(ax1)
ax1.set_title("Raw Spectra")
# Plot 2: Mean spectrum
SpectraPlot(x=wavenumbers, y=X.mean(axis=0), color='black').render(ax2)
ax2.set_title("Mean Spectrum")
plt.tight_layout()
plt.show()
その他の利用可能なプロット#
chemotools.plotting モジュールには、このガイドで扱っていない専用プロットも含まれています:
FeatureSelectionPlot: 特徴量の重要度および選択結果を可視化します。QQPlot: 残差の正規性を確認します。ResidualDistributionPlot: モデル残差の分布を解析します。YResidualsPlot: 残差を予測値に対してプロットします。
これらのクラスの詳細については API リファレンスを参照してください。