モデルを最適化する#
ケモメトリックスモデルを構築する際、アナリストはモデルの性能に大きく影響するハイパーパラメータについていくつかの選択を行う必要があります。ハイパーパラメータとは、モデルを訓練する前に設定されるパラメータです。一般的なハイパーパラメータには次のようなものがあります:
モデルはいくつの成分を使用すべきか?
Savitzky-Golay フィルタの最適なフィルタ長は?
どの多項式次数が最適か?
これらの質問に答えるために、通常はクロスバリデーションを用いてさまざまなハイパーパラメータの組み合わせをテストし、最も性能の高いモデルをもたらす組み合わせを見つけます。
このセクションでは、 chemotools と Scikit-Learn のモデル最適化オプション( GridSearchCV や RandomSearchCV など)を使用して、これらの選択を最適化するさまざまなオプションを調査します。これらは、ハイパーパラメータ空間を体系的に探索し、最適なハイパーパラメータを選択するのに役立ちます。
Probabl. の仲間たちによる、ハイパーパラメータ最適化に関する2つの優れた高度なリソースを以下に示します。
|
|


ハイパーパラメータ最適化#
例として、下の画像に示されているパイプラインのハイパーパラメータを最適化します。

パイプラインは以下のコードを使用して作成できます:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
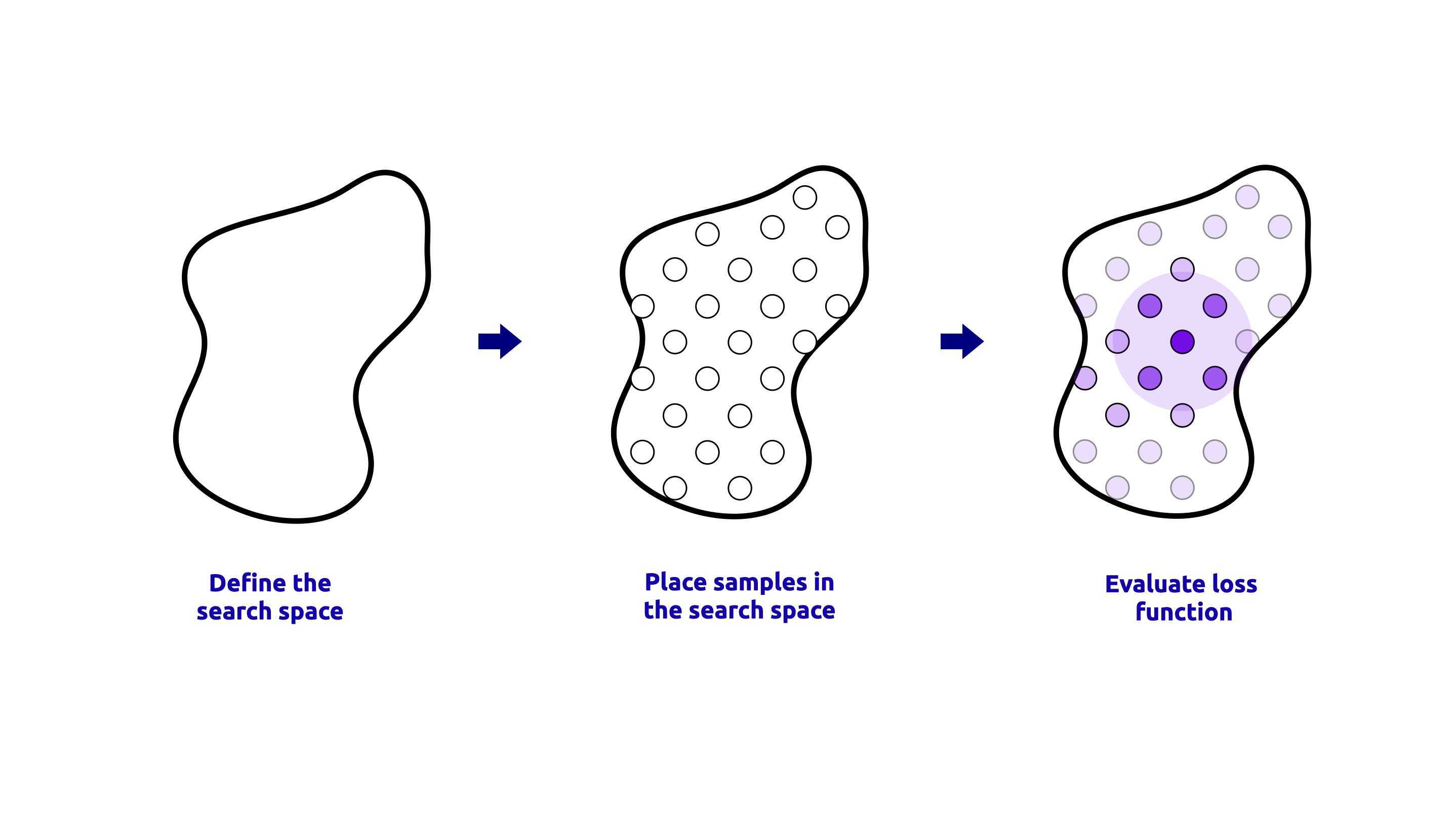
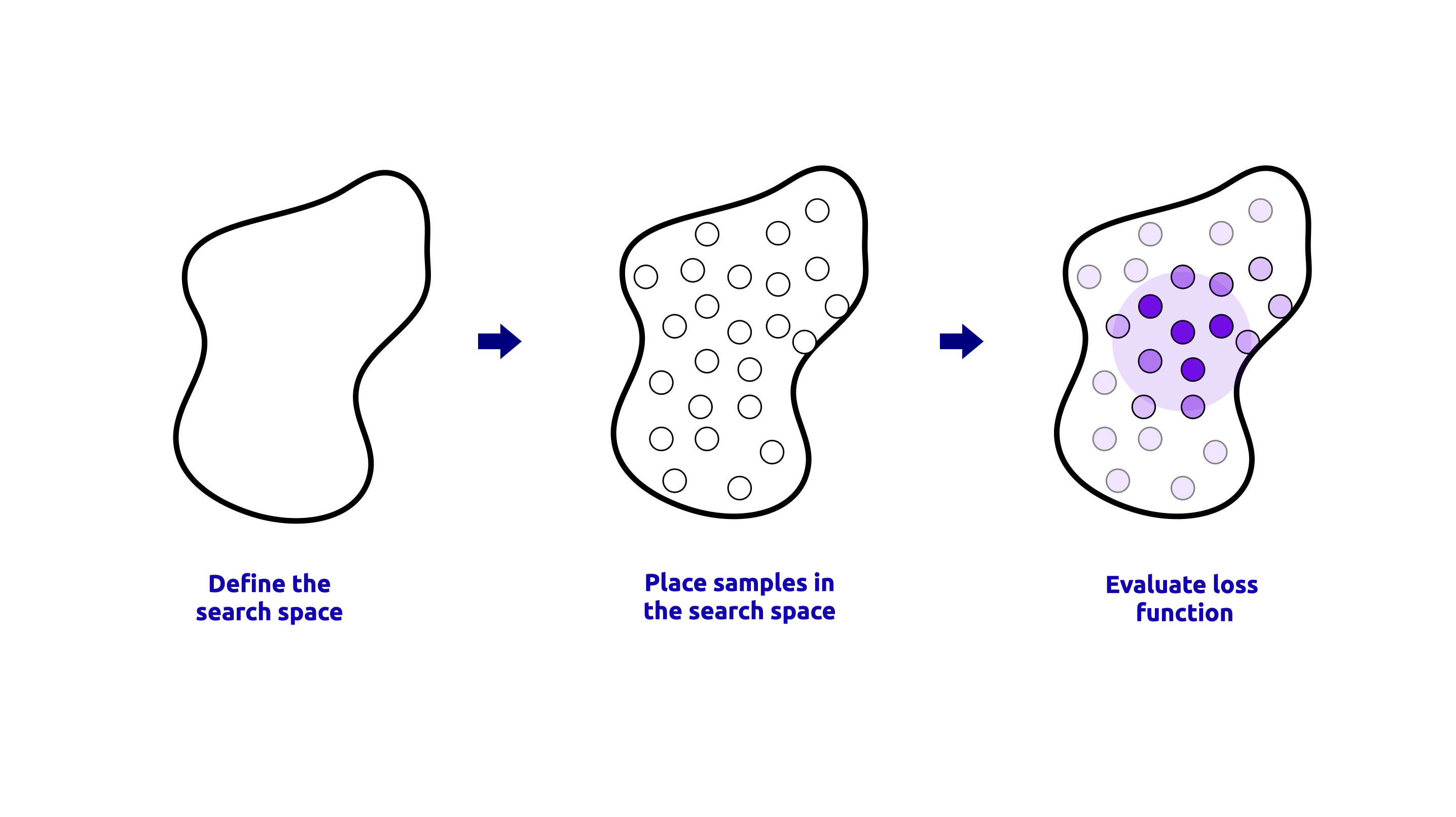
- すべてのハイパーパラメータ最適化手法は、次の3つのステップに従います:
すべての手法がハイパーパラメータ空間を探索し、最適なハイパーパラメータのセットを見つけます。
すべての手法がクロスバリデーションを使用して、各ハイパーパラメータセットの性能を評価します。
注釈
これらの手法の主な違いは、ハイパーパラメータ空間を探索する方法です。たとえば、 GridSearchCV は体系的にハイパーパラメータ空間を探索しますが、 RandomSearchCV はハイパーパラメータ空間から固定数のランダムな組み合わせをサンプリングします。
最初のステップは、ハイパーパラメータ空間を定義することです。今回の場合、次のハイパーパラメータを評価したいと考えています: - PLS 回帰モデルの成分数( n_components )- Savitzky-Golay フィルタのウィンドウサイズ( window_size )- Savitzky-Golay フィルタの多項式次数( polynomial_order )- Savitzky-Golay フィルタの微分次数( derivate_order )
ハイパーパラメータ空間を定義するには、ハイパーパラメータグリッドを辞書として定義します。キーはハイパーパラメータの名前で、値は各ハイパーパラメータの可能な値のリストです。ハイパーパラメータ空間を定義するコードは以下のとおりです:
# Define the hyperparameter space
param_grid = {
'plsregression__n_components': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'savitzkygolay__window_size': [5, 11, 21],
'savitzkygolay__polynomial_order': [2, 3],
'savitzkygolay__derivate_order': [0, 1]
}
次のステップは、ハイパーパラメータ空間内のサンプルの位置を定義することです。さまざまな戦略を調査します。
GridSearchCV#
GridSearchCV は、指定されたパラメータグリッドに対して網羅的な探索を実行する手法です。グリッド内のハイパーパラメータのすべての可能な組み合わせを評価し、クロスバリデーションに基づいて最高の性能を発揮するものを選択します。この手法は、ハイパーパラメータ空間が小さく、明確に定義されている場合に有用です。 GridSearchCV プロセスの視覚的表現を以下に示します:
GridSearchCV を実行するコードは以下のとおりです:
from sklearn.model_selection import GridSearchCV
# Define the GridSearchCV
grid_search = GridSearchCV(
pipeline,
param_grid=param_grid,
scoring='neg_mean_squared_error',
cv=5,
n_jobs=-1
)
# Fit the model
grid_search.fit(spectra, reference)
# Get the best hyperparameters
best_params = grid_search.best_params_
print("Best hyperparameters:", best_params)
# Get the best score
best_score = grid_search.best_score_
print("Best score:", best_score)
# Get the best estimator
best_estimator = grid_search.best_estimator_
print("Best estimator:", best_estimator)
GridSearchCV関数で注意すべき重要なパラメータがいくつかあります:scoringはモデルの性能を評価するために使用されるメトリックを指定します。この場合、スコアリングメトリックとして負の平均二乗誤差(MSE)を使用しています。cvは使用するクロスバリデーションのフォールド数を指定します。この場合、5分割クロスバリデーションを使用しています。n_jobsは並列実行するジョブの数を指定します。この場合、n_jobs=-1に設定することで利用可能なすべてのコアを使用しています。
注釈
🚀 複数のコアを活用すると、特にデータセットが大きい場合、ハイパーパラメータ最適化のプロセスが高速化されます。上記のビデオで示されているように、パイプラインの memory パラメータを使用して中間結果をキャッシュすることで、プロセスをさらに高速化できます!
RandomizedSearchCV#
RandomizedSearchCV は、ハイパーパラメータ空間から固定数のランダムな組み合わせをサンプリングし、クロスバリデーションを使用してそれらの性能を評価する手法です。この手法は、ハイパーパラメータ空間が大きく、明確に定義されている場合に有用です。 RandomizedSearchCV プロセスの視覚的表現を以下に示します:
RandomizedSearchCV を実行するコードは以下のとおりです:
from sklearn.model_selection import RandomizedSearchCV
# Define the RandomizedSearchCV
random_search = RandomizedSearchCV(
pipeline,
param_distributions=param_grid,
n_iter=10,
scoring='neg_mean_squared_error',
cv=5,
n_jobs=-1
)
# Fit the model
random_search.fit(spectra, reference)
# Get the best hyperparameters
best_params = random_search.best_params_
print("Best hyperparameters:", best_params)
# Get the best score
best_score = random_search.best_score_
print("Best score:", best_score)
# Get the best estimator
best_estimator = random_search.best_estimator_
print("Best estimator:", best_estimator)
n_iter パラメータは、ハイパーパラメータ空間からサンプリングするランダムな組み合わせの数を指定します。この場合、10個のランダムな組み合わせをサンプリングしています。 param_distributions パラメータは、サンプリング元のハイパーパラメータ空間を指定します。この場合、 GridSearchCV の例と同じハイパーパラメータ空間を使用しています。 scoring 、 cv 、および n_jobs パラメータは GridSearchCV の例と同じです。
注釈
上記のビデオで説明されているように、 RandomizedSearchCV はハイパーパラメータ空間内でより多くのデータポイントを探索できるため、特にハイパーパラメータ空間が大きい場合、 GridSearchCV よりも良い結果が得られる可能性があります。