前処理パイプライン#
パイプラインは機械学習ワークフローでますます人気が高まっています。本質的に、パイプラインは接続されたデータ処理ステップのシーケンスであり、あるステップの出力が次のステップの入力となります。これらは以下の点で非常に有用です:
複雑なワークフローの自動化、
効率の向上、
データ処理と分析におけるエラーの削減、そして
モデルの永続化とデプロイの簡素化。
chemotools のすべての前処理技術は scikit-learn と互換性があり、パイプラインで使用できます。例として、スペクトルに以下の前処理技術を適用したい場合を検討します:
範囲カット
線形補正
Savitzky-Golay微分
平均センタリング(標準スケーラー)
PLS回帰
従来のフロー#
従来のフローでは、以下の図に示すように、各前処理技術をスペクトルに個別に適用します:
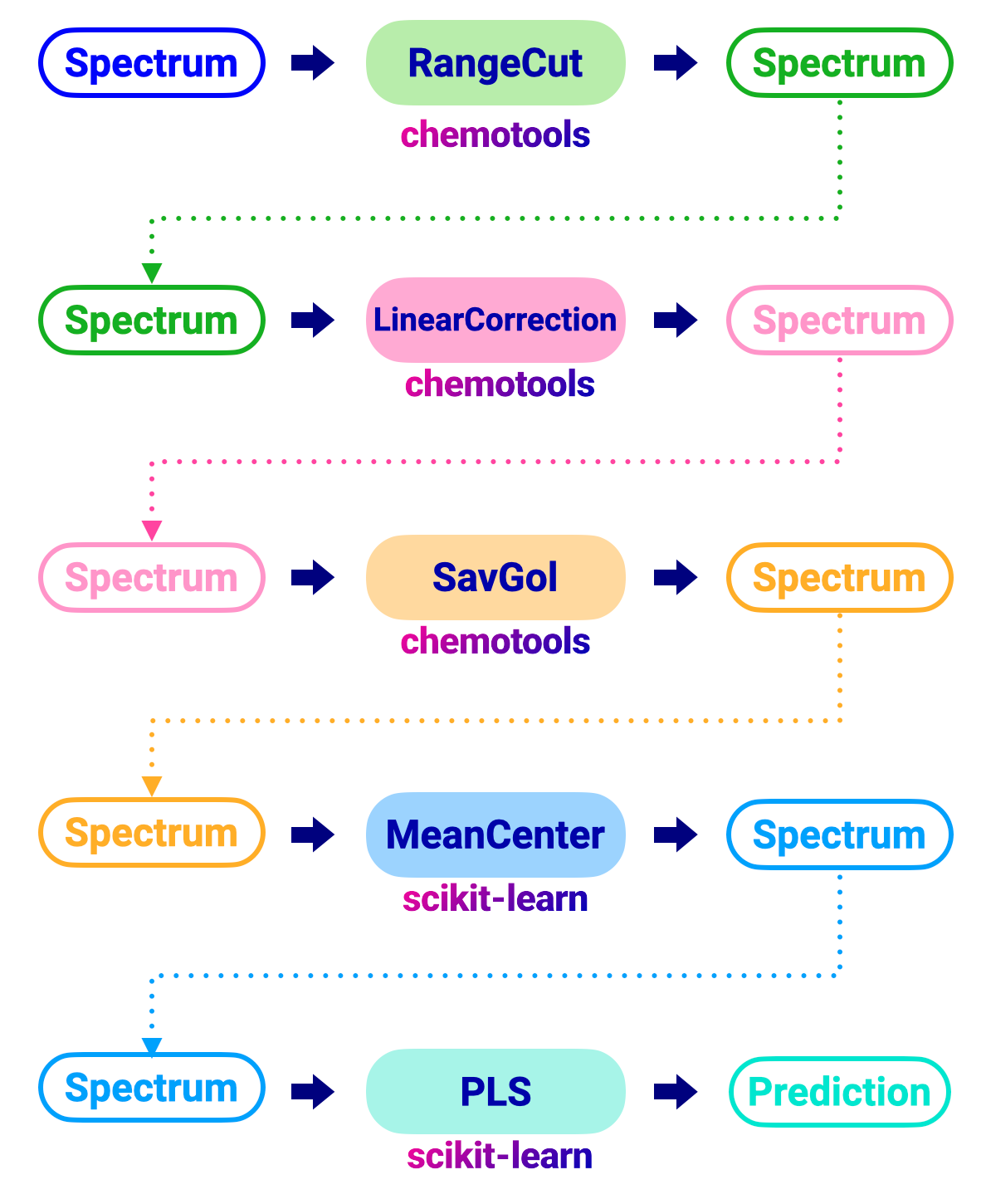
このワークフローを実行するコードは以下のようになります:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.preprocessing import StandardScaler
# Range Cut
# Define the Range Cut
range_cut = RangeCut(start=950, end=1550, wavenumbers=wavenumbers)
# Fit and apply Range Cut
spectra_cut = range_cut.fit_transform(spectra)
# Linear Correction
# Define the Linear Correction
linear_correction = LinearCorrection()
# Fit and apply Linear Correction
spectra_corrected = linear_correction.fit_transform(spectra_cut)
# Savitzky-Golay
# Define the Savitzky-Golay
savitzky_golay = SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1)
# Fit and apply Savitzky-Golay
spectra_derivate = savitzky_golay.fit_transform(spectra_corrected)
# Mean Centering (Standard Scaler)
# Define the Standard Scaler
standard_scaler = StandardScaler(with_mean=True, with_std=False)
# Fit and apply Standard Scaler
spectra_centered = standard_scaler.fit_transform(spectra_derivate)
# PLS regression
# Define the PLS regression
pls = PLSRegression(n_components=2, scale=False)
# Fit the model
pls.fit(spectra_centered, reference)
# Apply model to make predictions
prediction = pls.predict(spectra_centered)
これは退屈でエラーが発生しやすいワークフローであり、特に前処理ステップの数が増加すると顕著です。さらに、各前処理ステップを個別に永続化およびデプロイする必要があるため、モデルの永続化と本番環境へのデプロイは簡単ではありません。
パイプラインフロー#
パイプラインフローでは、すべての前処理ステップを単一のオブジェクトに結合できます。これによりワークフローが簡素化され、エラーのリスクが低減されます。以下の図は、同じワークフローをパイプラインを使用して示しています:

パイプラインを実行するコードの概要を以下の図に示します:

パイプラインを実行するコードを以下に示します:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
# Fit the model
pipeline.fit(spectra, reference)
# Apply model to make predictions
prediction = pipeline.predict(spectra)
パイプラインとスペクトルに適用される様々な前処理ステップを可視化できるようになりました。
Pipeline(steps=[('rangecut', RangeCut(end=1550, start=950)),
('linearcorrection', LinearCorrection()),
('savitzkygolay',
SavitzkyGolay(polynomial_order=2, window_size=21)),
('standardscaler', StandardScaler(with_std=False)),
('plsregression', PLSRegression(scale=False))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('rangecut', RangeCut(end=1550, start=950)),
('linearcorrection', LinearCorrection()),
('savitzkygolay',
SavitzkyGolay(polynomial_order=2, window_size=21)),
('standardscaler', StandardScaler(with_std=False)),
('plsregression', PLSRegression(scale=False))])RangeCut(end=1550, start=950)
LinearCorrection()
SavitzkyGolay(polynomial_order=2, window_size=21)
StandardScaler(with_std=False)
PLSRegression(scale=False)
注釈
従来のワークフローでは、異なる前処理オブジェクトを個別に永続化する必要があったことに注意してください。パイプラインワークフローでは、パイプライン全体を永続化し、本番環境にデプロイできます。詳細については モデルを永続化する セクションを参照してください。