モデルを永続化する#
以前、 chemotools を scikit-learn と組み合わせて使用し、データを前処理して予測を行う方法を見ました。しかし、実際のシナリオでは、訓練済み(フィット済み)のパイプラインを永続化して、本番環境にデプロイしたいと考えます。このセクションでは、モデルを永続化する2つの方法を紹介します:
pickleを使用するjoblibを使用する
ワークフローの概要を以下の画像に示します:
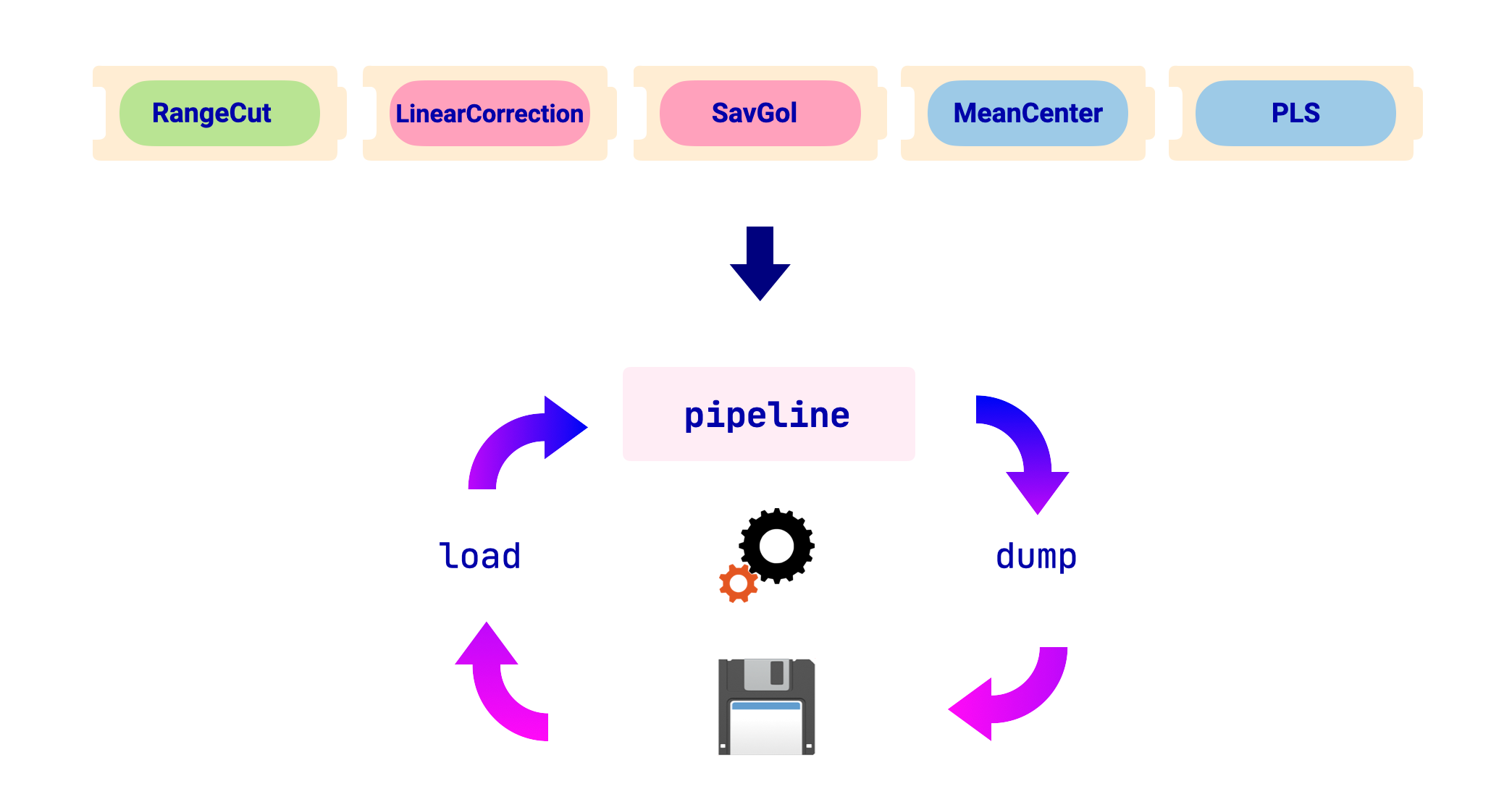
このセクションでは、以下のフィット済みパイプラインを例として使用します:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
# Fit the model
pipeline.fit(spectra, reference)
pickle を使用する#
pickle は、Python オブジェクト構造をシリアル化およびデシリアル化するためのバイナリプロトコルを実装する Python モジュールです。Python インストールに付属する標準モジュールです。以下のコードは、 pickle を使用して scikit-learn モデルを永続化する方法を示しています:
注釈
pickle モジュールは、誤ったデータや悪意を持って構築されたデータに対して安全ではありません。信頼できない、または認証されていないソースから受け取ったデータを決してアンピクルしないでください。
import pickle
# persist model
filename = 'model.pkl'
with open(filename, 'wb') as file:
pickle.dump(pipeline, file)
# load model
with open(filename, 'rb') as file:
pipeline = pickle.load(file)
joblib を使用する#
joblib は、NumPy データ構造を使用する Python オブジェクトを効率的に保存および読み込むためのユーティリティを提供する Python モジュールです。標準の Python インストールには含まれていませんが、 pip を使用してインストールできます。以下のコードは、 joblib を使用して scikit-learn モデルを永続化する方法を示しています:
from joblib import dump, load
# persist model
filename = 'model.joblib'
with open(filename, 'wb') as file:
dump(pipeline, file)
# load model
with open(filename, 'rb') as file:
pipeline = load(file)