优化模型#
在构建化学计量学模型时,分析人员需要做出几个关于超参数的选择,这些选择会显著影响模型的性能。超参数是在训练模型之前设置的参数。一些常见的超参数包括:
模型应该使用多少个组件?
Savitzky-Golay 滤波器的最佳滤波器长度是多少?
哪个多项式阶数效果最好?
为了回答这些问题,通常会使用交叉验证来测试和评估不同的超参数组合,以找到能够产生最佳性能模型的组合。
在本节中,我们将研究使用 chemotools 和 Scikit-Learn 的模型优化选项(如 GridSearchCV 或 RandomSearchCV)来优化这些选择的不同方法,这些方法将帮助系统地搜索超参数空间并选择最佳超参数。
以下是 Probabl. 的同行提供的两个优秀的超参数优化高级资源。
|
|


超参数优化#
作为一个示例,我们将优化下图中描述的管道中的超参数。

可以使用如下所示的代码创建管道:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
- 所有超参数优化方法都遵循以下三个步骤:
它们都探索超参数空间以找到最优的超参数集。
它们都使用交叉验证来评估每组超参数的性能。
备注
这些方法之间的主要区别在于它们探索超参数空间的方式。例如,GridSearchCV 系统地探索超参数空间,而 RandomSearchCV 从超参数空间中采样固定数量的随机组合。
第一步是定义超参数空间。在我们的案例中,我们希望评估以下超参数:- PLS 回归模型中的组件数量(n_components)- Savitzky-Golay 滤波器的窗口大小(window_size)- Savitzky-Golay 滤波器的多项式阶数(polynomial_order)- Savitzky-Golay 滤波器的导数阶数(derivate_order)
为了定义超参数空间,我们可以将超参数网格定义为字典,其中键是超参数的名称,值是每个超参数的可能值列表。定义超参数空间的代码如下所示:
# Define the hyperparameter space
param_grid = {
'plsregression__n_components': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'savitzkygolay__window_size': [5, 11, 21],
'savitzkygolay__polynomial_order': [2, 3],
'savitzkygolay__derivate_order': [0, 1]
}
下一步是定义样本在超参数空间中的位置。我们将研究不同的策略。
GridSearchCV#
GridSearchCV 是一种在指定参数网格上执行穷举搜索的方法。它评估网格中所有可能的超参数组合,并基于交叉验证选择性能最佳的组合。当超参数空间较小且定义明确时,此方法很有用。GridSearchCV 过程的可视化表示如下所示:
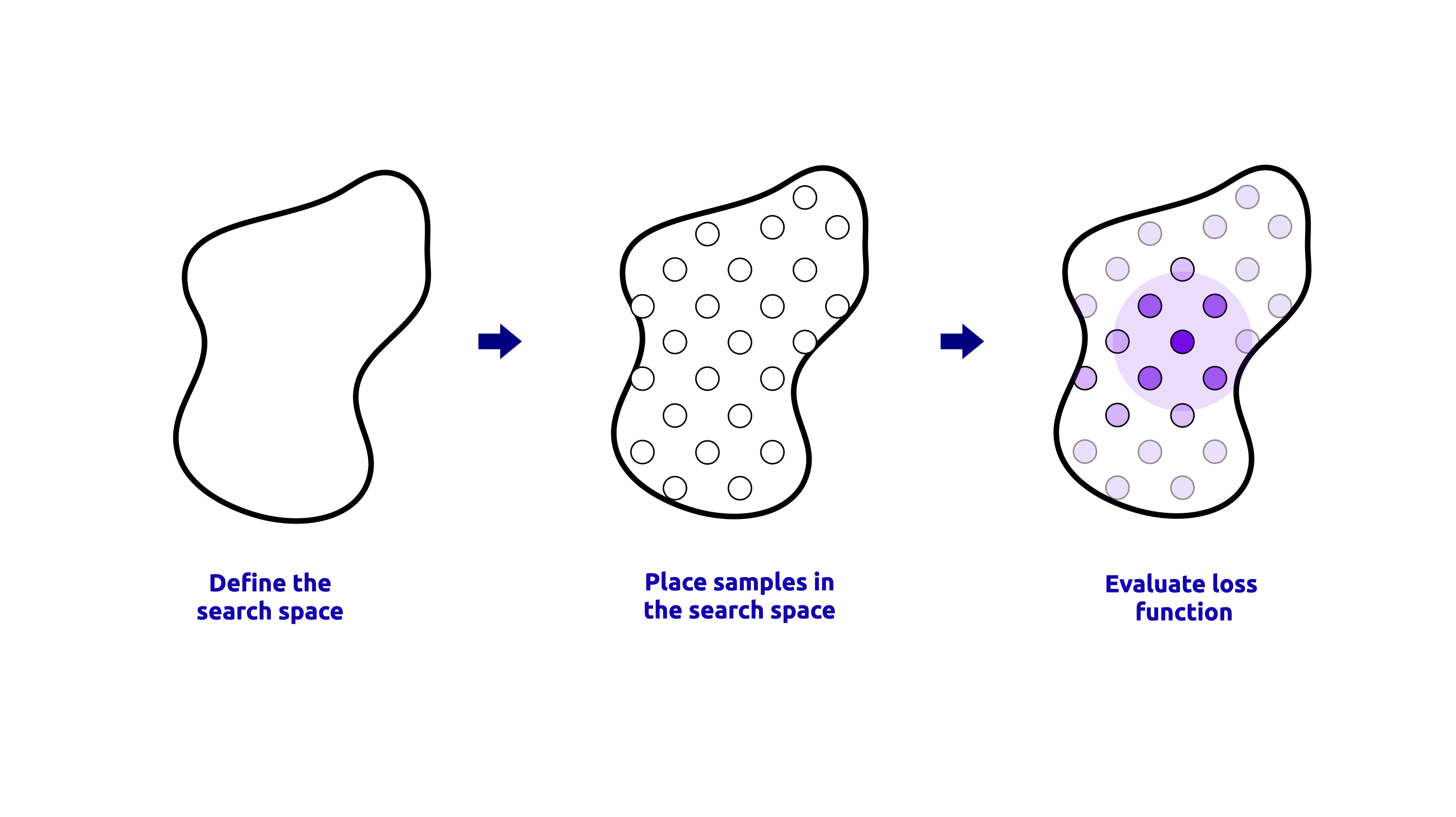
执行 GridSearchCV 的代码如下所示:
from sklearn.model_selection import GridSearchCV
# Define the GridSearchCV
grid_search = GridSearchCV(
pipeline,
param_grid=param_grid,
scoring='neg_mean_squared_error',
cv=5,
n_jobs=-1
)
# Fit the model
grid_search.fit(spectra, reference)
# Get the best hyperparameters
best_params = grid_search.best_params_
print("Best hyperparameters:", best_params)
# Get the best score
best_score = grid_search.best_score_
print("Best score:", best_score)
# Get the best estimator
best_estimator = grid_search.best_estimator_
print("Best estimator:", best_estimator)
- 在
GridSearchCV函数中有几个重要参数需要注意: scoring指定用于评估模型性能的指标。在这种情况下,我们使用负均方误差(MSE)作为评分指标。cv指定要使用的交叉验证折数。在这种情况下,我们使用 5 折交叉验证。n_jobs指定并行运行的作业数。在这种情况下,我们通过设置n_jobs=-1来使用所有可用的核心。
备注
🚀 利用多核将加速超参数优化的过程,尤其是在数据集较大时。您可以通过在管道中使用 memory 参数缓存中间结果来进一步加速该过程,如上方的视频所示!
RandomizedSearchCV#
RandomizedSearchCV 是一种从超参数空间中采样固定数量的随机组合,并使用交叉验证评估其性能的方法。当超参数空间较大且定义明确时,此方法很有用。RandomizedSearchCV 过程的可视化表示如下所示:
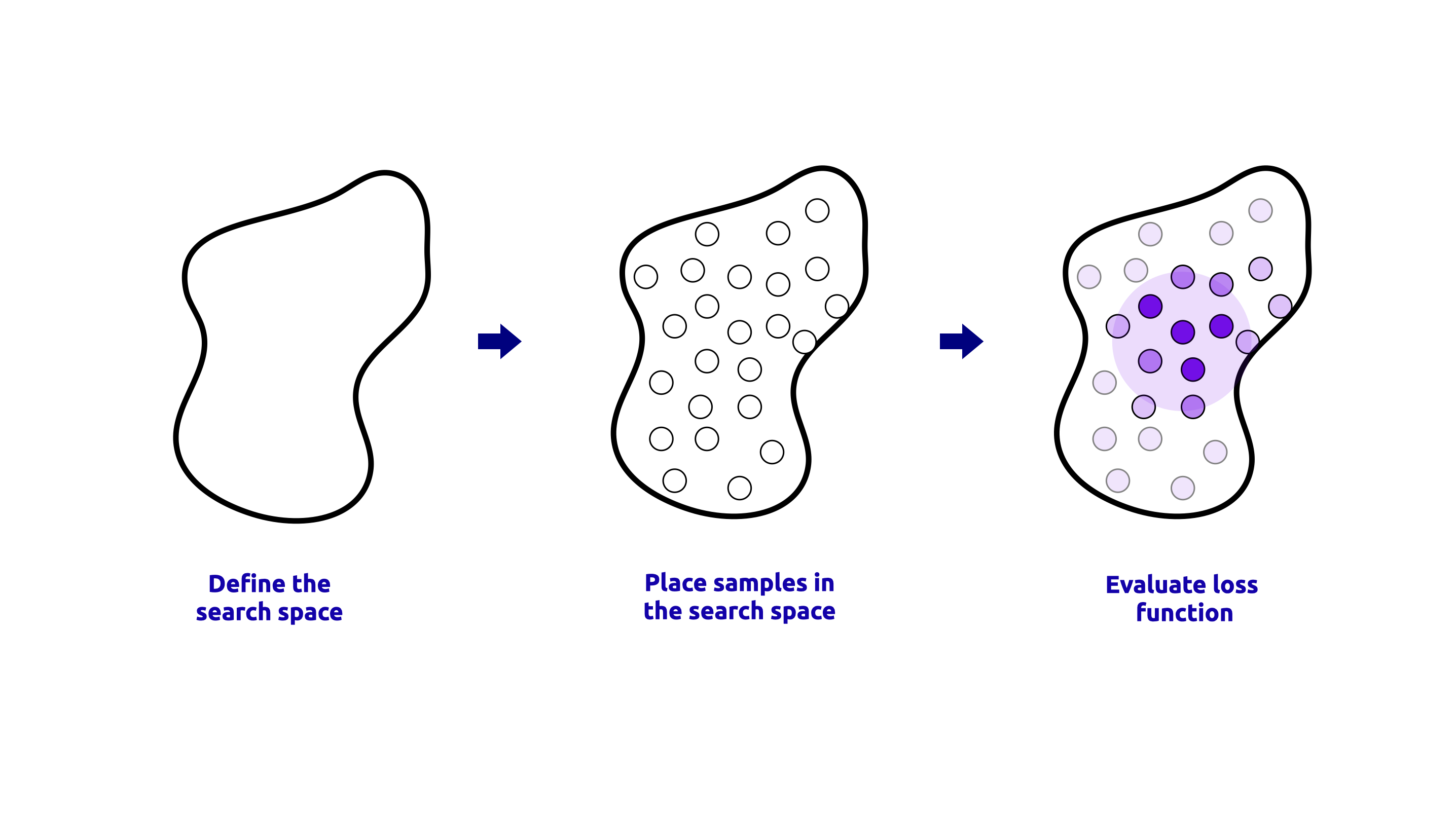
执行 RandomizedSearchCV 的代码如下所示:
from sklearn.model_selection import RandomizedSearchCV
# Define the RandomizedSearchCV
random_search = RandomizedSearchCV(
pipeline,
param_distributions=param_grid,
n_iter=10,
scoring='neg_mean_squared_error',
cv=5,
n_jobs=-1
)
# Fit the model
random_search.fit(spectra, reference)
# Get the best hyperparameters
best_params = random_search.best_params_
print("Best hyperparameters:", best_params)
# Get the best score
best_score = random_search.best_score_
print("Best score:", best_score)
# Get the best estimator
best_estimator = random_search.best_estimator_
print("Best estimator:", best_estimator)
n_iter 参数指定要从超参数空间中采样的随机组合数量。在这种情况下,我们采样 10 个随机组合。param_distributions 参数指定要从中采样的超参数空间。在这种情况下,我们使用与 GridSearchCV 示例中相同的超参数空间。scoring、cv 和 n_jobs 参数与 GridSearchCV 示例中的相同。
备注
如上方的视频所述,RandomizedSearchCV 允许在超参数空间中探索更多的数据点,这可能导致比 GridSearchCV 更好的结果,尤其是在超参数空间较大时。