检查您的模型#
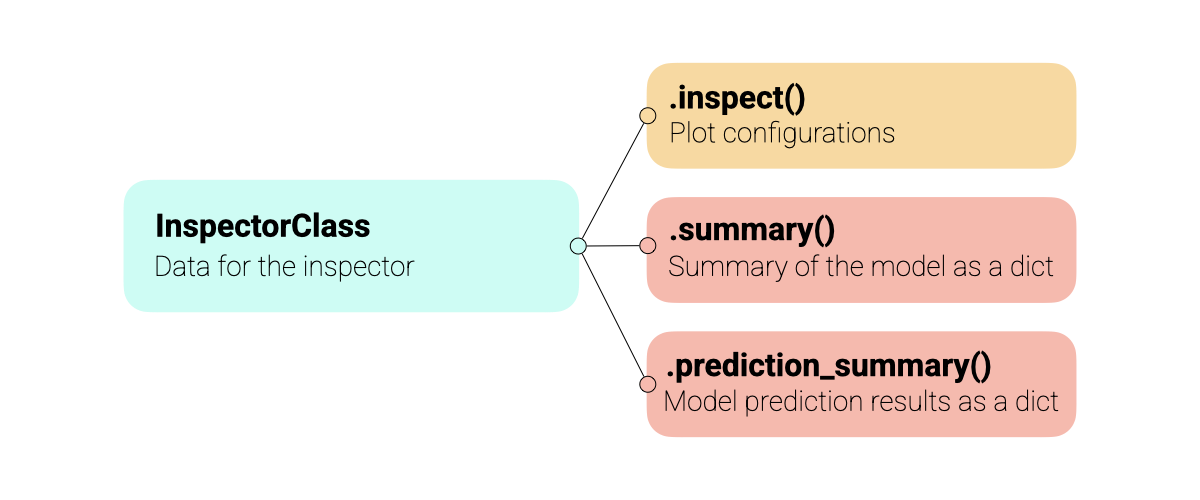
chemotools.inspector 模块为模型诊断提供了一个统一的接口。无需手动为得分、载荷和离群值分别创建图表,Inspector(检查器) 只需一次方法调用即可生成完整的诊断套件。
所有检查器共享相同的 API,使得在不同模型类型(PCA、PLS 等)间使用变得直观。检查器支持多个数据集(训练集、测试集、验证集),并提供广泛的着色、注释和成分选择等自定义选项。下图展示了检查器的抽象概述。
警告
检查器模块目前处于实验阶段,正在积极开发中。其 API 可能在未来的版本中发生变化。我们欢迎您的反馈!请在此报告问题或建议:paucablop/chemotools#issues
为何使用检查器?#
减少样板代码,使您的模型流程更具可读性,并确保能完全理解您的模型:
单行诊断:使用
.inspect()生成所有标准图表(得分、载荷、方差、离群值)。统一接口:为 PCA 和 PLS 模型提供一致的 API。
多数据集支持:可在同一图表中轻松比较训练集、测试集和验证集。
光谱比较:使用
.inspect_spectra()比较原始光谱与预处理后的光谱。预处理可视化: 使用
PreprocessingInspector逐步查看管道的每个步骤对数据的影响。数据访问:提取得分、载荷和系数以进行自定义分析。
交互式且适合发表:返回标准的 matplotlib 图形,可进行进一步自定义。
基本用法#
目前,chemotools 支持以下模型的检查器:
预处理:
PreprocessingInspectorPCA:
PCAInspectorPLS 回归:
PLSRegressionInspector
在本示例中,让我们加载一些数据并训练一个 PCA 和一个 PLS 回归模型。
from sklearn.cross_decomposition import PLSRegression
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from chemotools.datasets import load_fermentation_train
from chemotools.derivative import SavitzkyGolay
from chemotools.feature_selection import RangeCut
from chemotools.inspector import PCAInspector, PLSRegressionInspector, PreprocessingInspector
# 1. Load Data
X, y = load_fermentation_train()
wn = X.columns
# 2. Fit the PCA Model
pca = make_pipeline(
RangeCut(start=900, end=1400, wavenumbers=wn),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=0),
StandardScaler(with_std=False),
PCA(n_components=3),
)
pca.fit(X)
# 3. Fit the PLS regression model
pls = make_pipeline(
RangeCut(start=900, end=1400, wavenumbers=wn),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
PLSRegression(n_components=3, scale=False),
)
pls.fit(X, y)
现在我们已经训练好模型,可以使用 inspector 来检查它们。该模块的核心是 .inspect() 方法,所有检查器都共享此方法。
备注
inspect() 方法返回一个包含 matplotlib.figure.Figure 对象的字典,允许您单独保存或修改它们。
检查预处理步骤#
PreprocessingInspector 允许你可视化管道中每个预处理步骤的累积效果。与检查最终模型不同,它关注的是**数据在每一步转换中的变化方式**。
使用我们在上面定义的同一个 PCA 管道,我们可以检查每个预处理步骤如何对数据进行转换:
# Inspect the preprocessing steps of the PCA pipeline
inspector = PreprocessingInspector(pca, X_train=X, y_train=y, x_axis=wn)
figures = inspector.inspect()
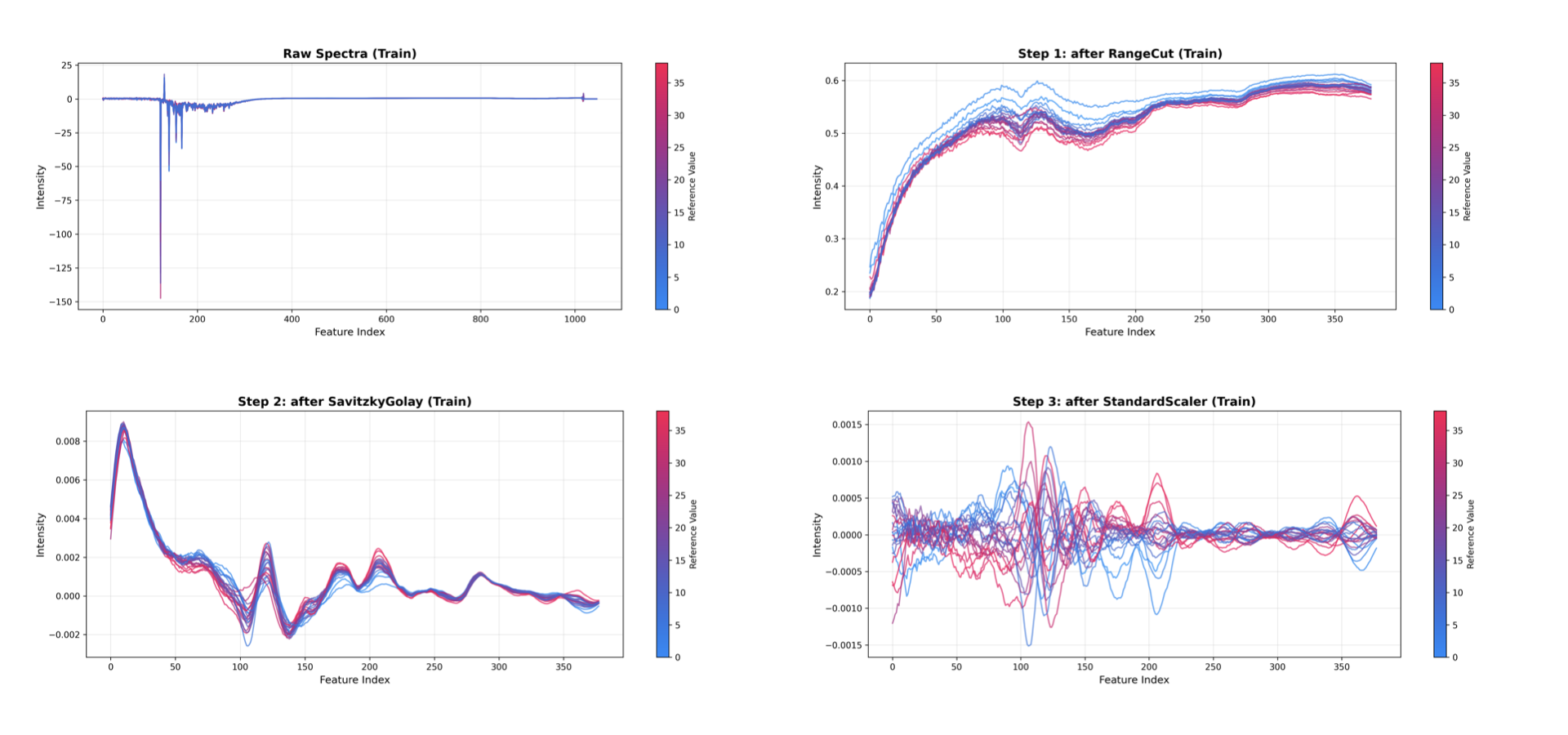
这会为每个预处理步骤生成一个图,先显示原始数据,随后显示每次转换后的累积结果:
原始光谱:原始输入数据。
RangeCut 之后:选择感兴趣的光谱区域后的数据。
SavitzkyGolay 之后:平滑处理后的数据。
StandardScaler 之后:进行均值中心化后的数据。
模型步骤(例如 PCA、PLS)会自动从可视化中排除。
PreprocessingInspector 还支持多数据集比较。你可以叠加训练集、测试集和验证集的数据,以验证预处理在不同数据集之间是否表现一致:
from sklearn.model_selection import train_test_split
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0
)
# Initialize the inspector with both train and test data
inspector = PreprocessingInspector(
pca,
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
x_axis=wn,
)
figures = inspector.inspect(dataset=['train', 'test'])
备注
PreprocessingInspector 还提供 inspect_spectra() 方法,用于快速比较 原始数据与完全预处理后的数据,以及 summary() 方法,该方法会返回一个包含管道信息的类型化 dataclass。
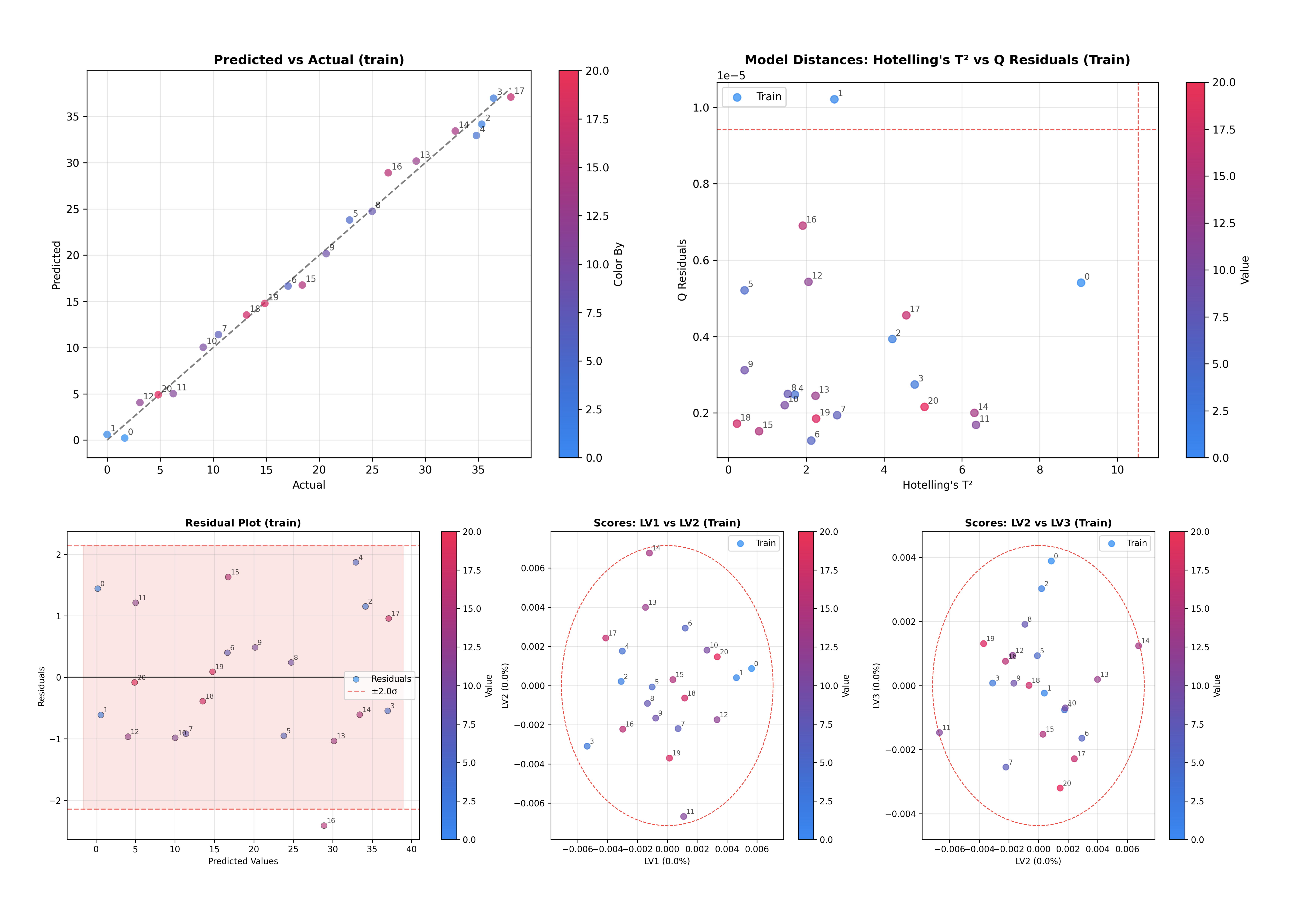
检查 PCA 模型#
接下来,我们看一下 PCA 模型。
# Inspect the PCA model
inspector = PCAInspector(pca, X_train=X, y_train=y, x_axis=wn)
figures = inspector.inspect()
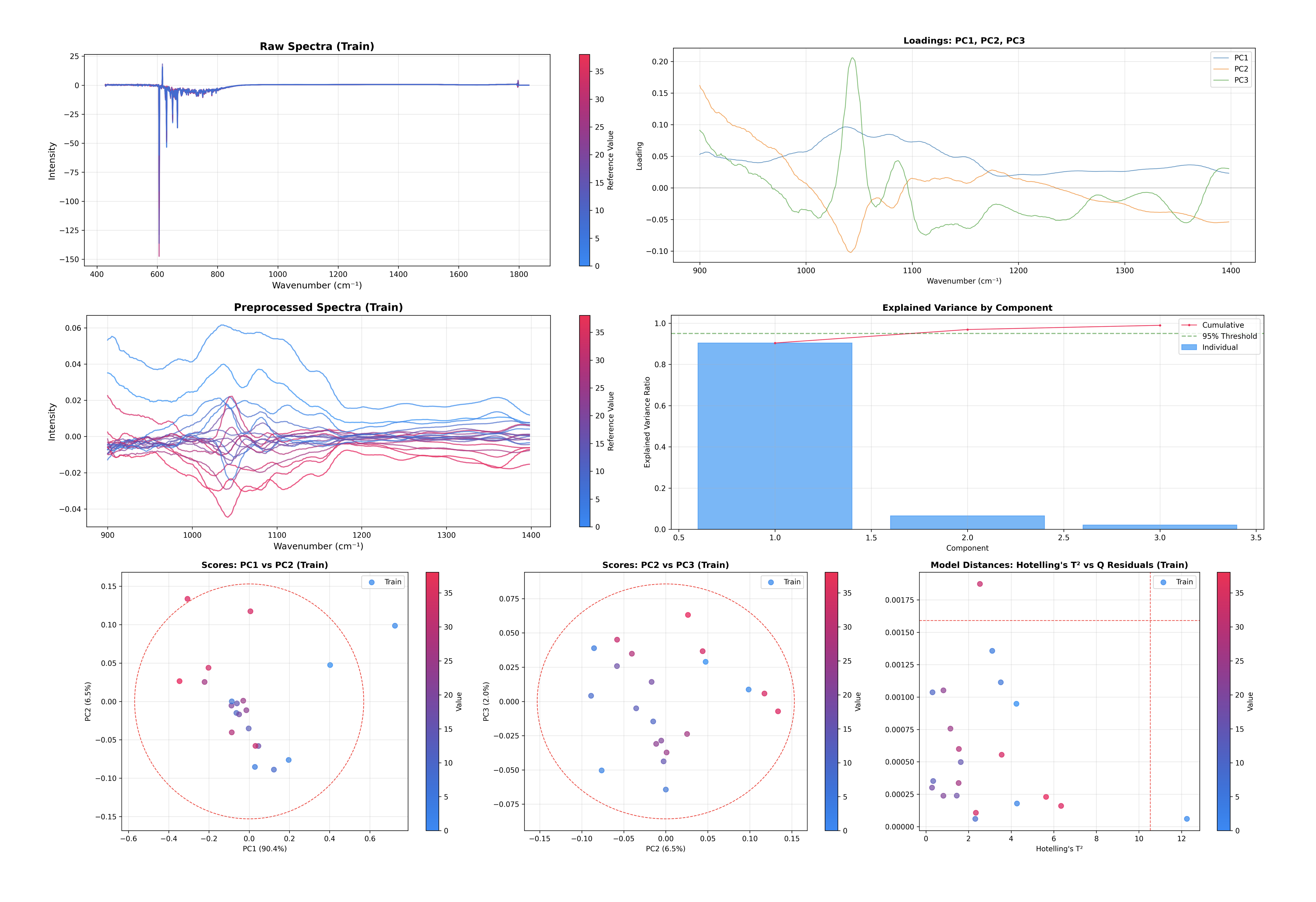
这一条命令生成并显示几个关键的诊断图表:
解释方差:帮助您决定是否拥有足够的成分。
得分图:可视化样本空间(PC1 对 PC2,PC2 对 PC3)。
载荷图:可视化特征空间(模型正在观察的内容)。
离群值检测:霍特林 T² 与 Q 残差图。
检查 PLS 回归模型#
PLS 回归检查器与 PCAInspector 共享相同的 API,使得在它们之间切换很容易。
# Inspect the PLS Regression model
inspector = PLSRegressionInspector(pls, X_train=X, y_train=y, x_axis=wn)
figures = inspector.inspect()
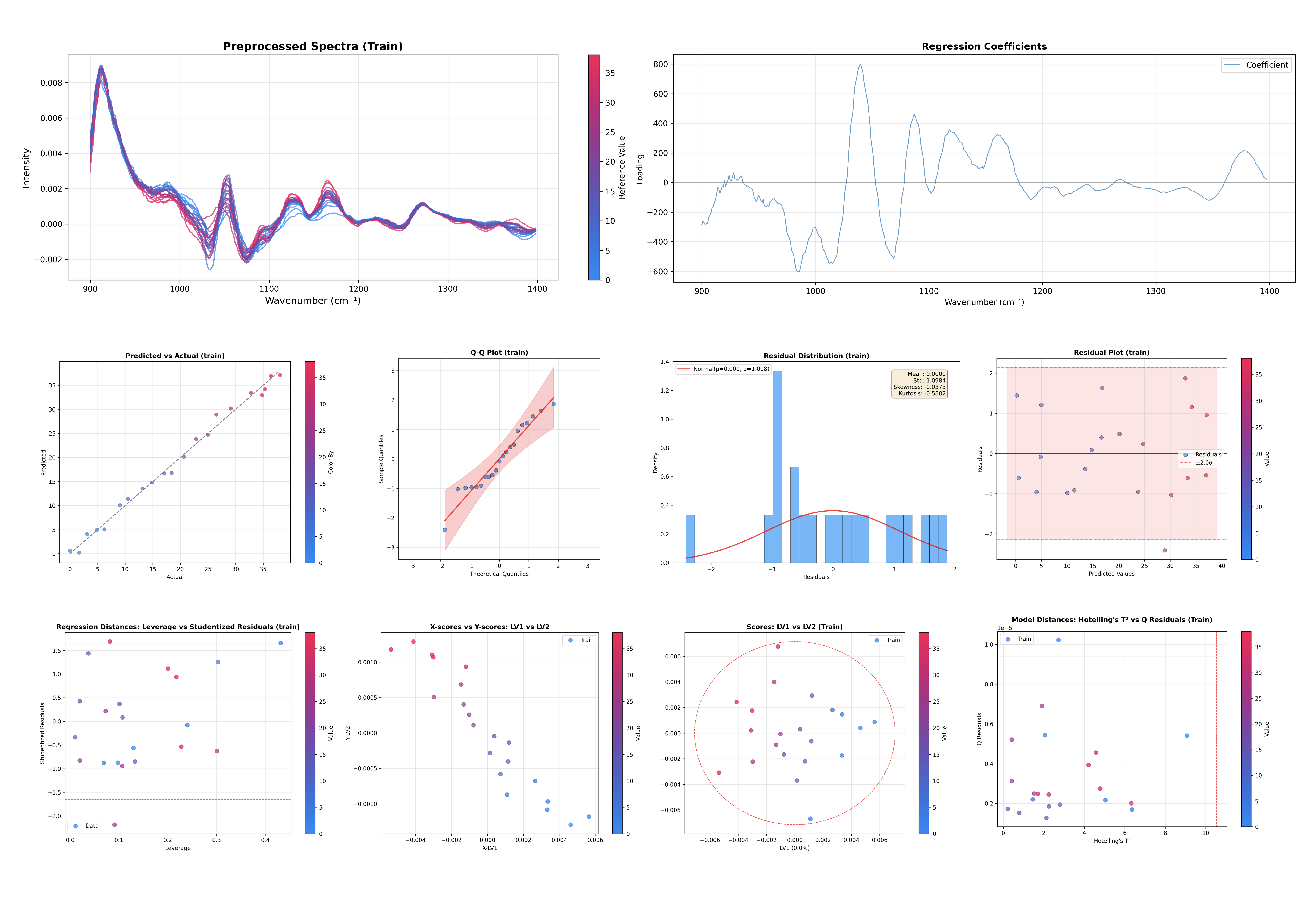
此命令生成专为 PLS 回归定制的诊断图表:
解释方差:针对 X 空间和 Y 空间。
得分图:可视化样本空间(LV1 对 LV2)。
X 得分与 Y 得分:潜在变量之间的相关性。
载荷图:X 载荷、X 权重和 X 旋转。
回归系数:预测的特征重要性。
离群值检测:霍特林 T² 与 Q 残差图。
杠杆与学生化残差:有影响力的观测点检测。
Q 残差与 Y 残差:组合模型拟合诊断。
预测值与实际值:评估回归性能。
Y 残差图:识别预测误差中的模式。
Q-Q 图:检查残差的正态性。
残差分布:预测误差的直方图。
检查光谱#
当您的模型包含预处理步骤(例如 sklearn Pipeline)时,您可以使用 .inspect_spectra() 方法比较原始光谱和预处理后的光谱:
# Compare raw vs preprocessed spectra
spectra_figures = inspector.inspect_spectra()
这会生成两个图表:
原始光谱:任何变换前的原始输入数据。
预处理后的光谱:所有预处理步骤之后(模型之前)的数据。
这在光谱学工作流程中尤其有用,可验证预处理步骤(基线校正、导数、归一化)是否按预期工作。
备注
inspect_spectra() 方法仅在模型是包含预处理步骤的 Pipeline 时才可用。当存在预处理时,.inspect() 也会自动调用它。
自定义检查#
inspect() 方法具有高度可定制性。您可以控制绘制哪些成分、如何为样本着色以及包含哪些数据集。
选择成分#
您可以指定在得分图和载荷图中可视化哪些成分。
# Plot LV2 vs LV3 for scores, and the first 2 components for loadings
inspector.inspect(
components_scores=(1, 2),
loadings_components=[0, 1]
)
components_scores 参数接受:
int:绘制前 N 个成分与样本索引的关系图
tuple (i, j):绘制成分 i 对成分 j 的关系图
list:多个规格,例如
[(0, 1), (1, 2)]
着色与注释#
默认情况下,图表根据目标变量 y (如果提供)进行着色。您可以使用 color_by 和 annotate_by 参数来自定义此行为。
# Color by y and annotate by sample index
inspector.inspect(color_by='y', annotate_by='sample_index')
这两个参数都接受:
'y':根据目标变量着色/注释。'sample_index':根据样本索引着色/注释。array-like:与样本数量长度相同的自定义值。
dict:将数据集名称映射到数组以用于多数据集绘图,例如
{'train': array1, 'test': array2}。
颜色模式#
color_mode 参数控制颜色的应用方式:
# Use categorical coloring (discrete colors for each unique value)
inspector.inspect(color_by='y', color_mode='categorical')
# Use continuous coloring (gradient based on values) - default
inspector.inspect(color_by='y', color_mode='continuous')
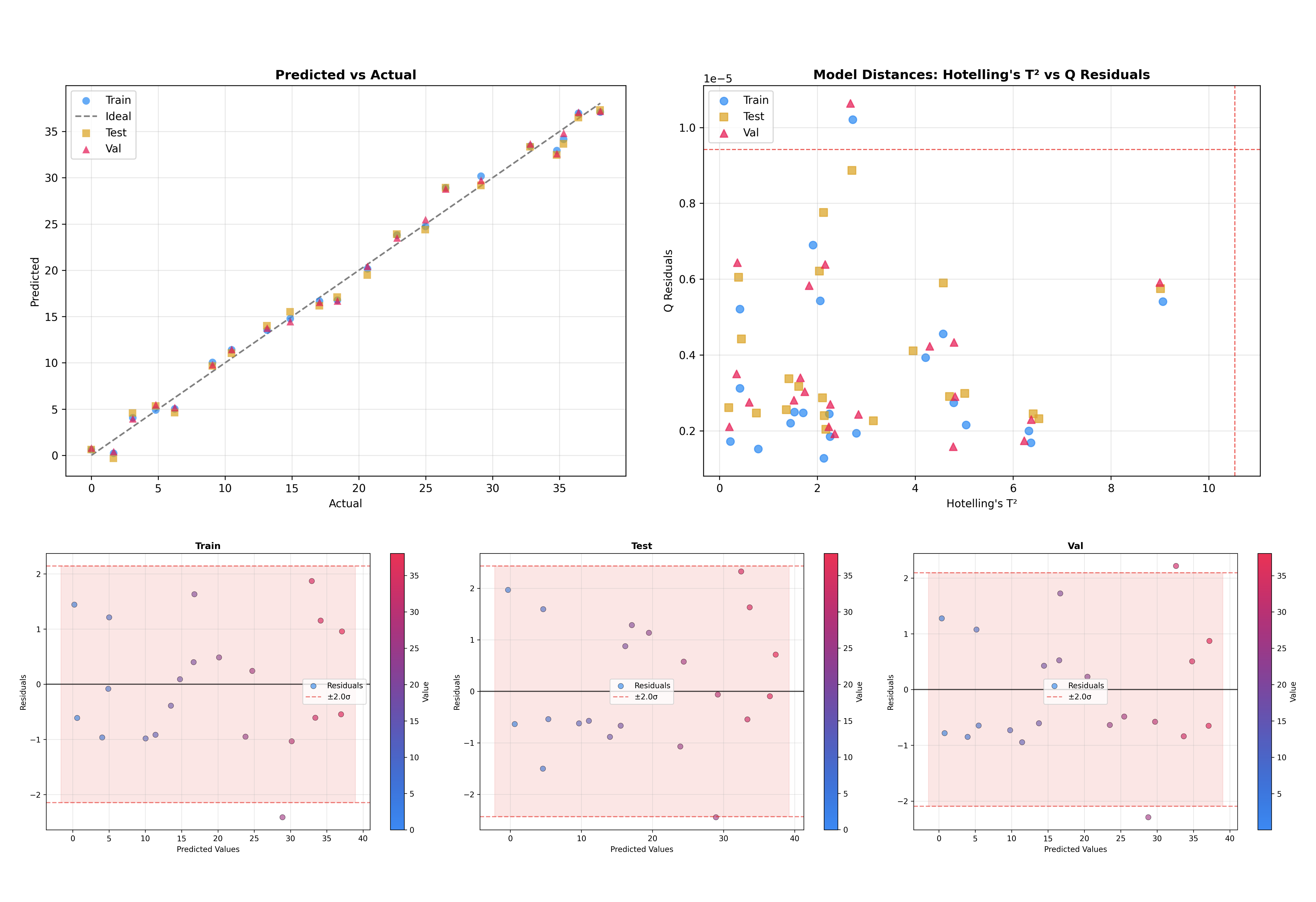
比较数据集#
另一个有用的功能是能够叠加多个数据集。这对于检查模型对未见数据的泛化能力至关重要。
# Initialize inspector with train, test, and validation data
inspector = PLSRegressionInspector(
pls,
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
X_val=X_val,
y_val=y_val,
x_axis=wn,
)
# Inspect all datasets together
figures = inspector.inspect(dataset=['train', 'test', 'val'])
这将生成将训练、测试和验证样本一起可视化的图表,使得很容易发现域偏移或过拟合。
多输出 PLS#
对于多输出 PLS 模型(多个目标变量),使用 target_index 参数选择要检查的目标:
# Inspect the second target variable (index 1)
inspector.inspect(target_index=1)
绘图配置#
要精细控制图形大小,请使用 plot_config 参数或直接传递尺寸参数:
from chemotools.inspector import InspectorPlotConfig
# Using plot_config
config = InspectorPlotConfig(
scores_figsize=(10, 8),
loadings_figsize=(12, 4),
variance_figsize=(8, 6),
)
inspector.inspect(plot_config=config)
# Or pass sizes directly as kwargs
inspector.inspect(scores_figsize=(10, 8))
处理图形#
inspect() 方法返回一个包含 matplotlib.figure.Figure 对象的字典。这允许您访问单个图表、进一步自定义它们或将它们保存到文件。
访问单个图表#
返回字典中的每个图形都有一个描述性键名:
# Get all figures
figures = inspector.inspect()
# See available figure keys
print(figures.keys())
# dict_keys(['variance_x', 'variance_y', 'loadings_x', 'loadings_weights',
# 'loadings_rotations', 'regression_coefficients', 'scores_1',
# 'scores_2', 'x_vs_y_scores_1', 'distances_hotelling_q', ...])
# Access a specific figure
scores_fig = figures['scores_1']
loadings_fig = figures['loadings_x']
可用的图形键名取决于检查器类型:
PCAInspector:
variance:解释方差图loadings:载荷图scores_1,scores_2, ...:得分图distances:霍特林 T² 与 Q 残差图
PLSRegressionInspector:
variance_x,variance_y:解释方差图loadings_x,loadings_weights,loadings_rotations:载荷图regression_coefficients:系数图scores_1,scores_2, ...:X 得分图x_vs_y_scores_1,x_vs_y_scores_2, ...:X 与 Y 得分图distances_hotelling_q:霍特林 T² 与 Q 残差图distances_leverage_studentized:杠杆与学生化残差图distances_q_y_residuals:Q 残差与 Y 残差图predicted_vs_actual:预测值与实际值图residuals:Y 残差图qq_plot:Q-Q 图residual_distribution:残差直方图raw_spectra,preprocessed_spectra:光谱图(如果存在预处理)
保存图形#
您可以保存单个图形或一次性保存所有图形:
# Save a single figure
figures['scores_1'].savefig('scores_plot.png', dpi=300, bbox_inches='tight')
# Save as PDF for publications
figures['loadings_x'].savefig('loadings.pdf', bbox_inches='tight')
# Save all figures to a directory
import os
output_dir = 'model_diagnostics'
os.makedirs(output_dir, exist_ok=True)
for name, fig in figures.items():
fig.savefig(f'{output_dir}/{name}.png', dpi=300, bbox_inches='tight')
自定义图形#
由于这些图形是标准的 matplotlib 对象,您可以在创建后修改它们:
# Get a figure and customize it
fig = figures['scores_1']
ax = fig.axes[0]
# Modify title, labels, etc.
ax.set_title('My Custom Title', fontsize=14, fontweight='bold')
ax.set_xlabel('Latent Variable 1')
ax.set_ylabel('Latent Variable 2')
# Add annotations, lines, etc.
ax.axhline(y=0, color='gray', linestyle='--', alpha=0.5)
ax.axvline(x=0, color='gray', linestyle='--', alpha=0.5)
# Update the figure
fig.tight_layout()
访问模型数据#
除了绘图,检查器还提供了提取底层数据以进行自定义分析的方法。
PCA 检查器#
inspector = PCAInspector(pca, X_train=X, y_train=y, x_axis=wn)
# Get scores for a dataset
scores = inspector.get_scores('train') # Shape: (n_samples, n_components)
# Get loadings (optionally select components)
loadings = inspector.get_loadings() # All components
loadings = inspector.get_loadings([0, 1]) # First two components
# Get explained variance ratio
variance = inspector.get_explained_variance_ratio()
PLS 回归检查器#
inspector = PLSRegressionInspector(pls, X_train=X, y_train=y, x_axis=wn)
# X-space scores and loadings
x_scores = inspector.get_x_scores('train')
x_loadings = inspector.get_x_loadings()
x_weights = inspector.get_x_weights()
x_rotations = inspector.get_x_rotations()
# Y-space scores
y_scores = inspector.get_y_scores('train')
# Regression coefficients
coefficients = inspector.get_regression_coefficients()
# Explained variance in X and Y space
x_variance = inspector.get_explained_x_variance_ratio()
y_variance = inspector.get_explained_y_variance_ratio()
模型摘要#
检查器通过 .summary() 方法提供模型的汇总统计信息。这会返回一个数据类对象,其中包含 .to_dict() 方法,便于转换为字典。
模型摘要#
# Get model summary
summary = inspector.summary()
# Access as object attributes
print(summary.model_type) # 'PLSRegression'
print(summary.n_components) # 3
print(summary.n_features) # 1047
# Convert to dictionary
summary.to_dict()
.to_dict() 方法返回:
{
'model_type': 'PLSRegression',
'has_preprocessing': True,
'n_features': 1047,
'n_components': 3,
'n_samples': {'train': 21, 'test': 21, 'val': 21},
'preprocessing_steps': [
{'step': 1, 'name': 'rangecut', 'type': 'RangeCut'},
{'step': 2, 'name': 'savitzkygolay', 'type': 'SavitzkyGolay'}
],
'hotelling_t2_limit': 12.34,
'q_residuals_limit': 0.56,
'train': {'rmse': 1.07, 'r2': 0.99, 'bias': 0.01},
'test': {'rmse': 1.21, 'r2': 0.99, 'bias': -0.02},
...
}
回归指标#
对于 PLS 回归模型,您可以直接从摘要对象访问回归指标:
summary = inspector.summary()
# Access metrics for specific datasets
print(summary.train.rmse) # 1.07
print(summary.train.r2) # 0.99
print(summary.test.bias) # -0.02
.metrics 属性提供了一个针对 pandas.DataFrame 优化的结构:
import pandas as pd
# Get metrics in DataFrame-friendly format
pd.DataFrame(inspector.summary().metrics).T
| train | test | val | |
|---|---|---|---|
| rmse | 1.930431e+00 | 2.717529 | 13.107082 |
| r2 | 9.746810e-01 | 0.949825 | -0.167189 |
| bias | -8.035900e-16 | 1.882106 | -12.964854 |