Pipelines de preprocesamiento#
Los pipelines se están volviendo cada vez más populares en flujos de trabajo de aprendizaje automático. En esencia, los pipelines son una secuencia de pasos de procesamiento de datos conectados, donde la salida de un paso es la entrada del siguiente. Son muy útiles para:
automatizar flujos de trabajo complejos,
mejorar la eficiencia,
reducir errores en el procesamiento y análisis de datos y
simplificar la persistencia y el despliegue de modelos.
Todas las técnicas de preprocesamiento en chemotools son compatibles con scikit-learn y se pueden usar en pipelines. Como ejemplo, estudiaremos el caso donde queremos aplicar las siguientes técnicas de preprocesamiento a nuestros espectros:
Corte de rango
Corrección lineal
Derivada de Savitzky-Golay
Centrado de media (Standard Scaler)
Regresión PLS
Flujo tradicional#
En un flujo tradicional, aplicaríamos cada técnica de preprocesamiento individualmente a los espectros como se muestra en la imagen a continuación:
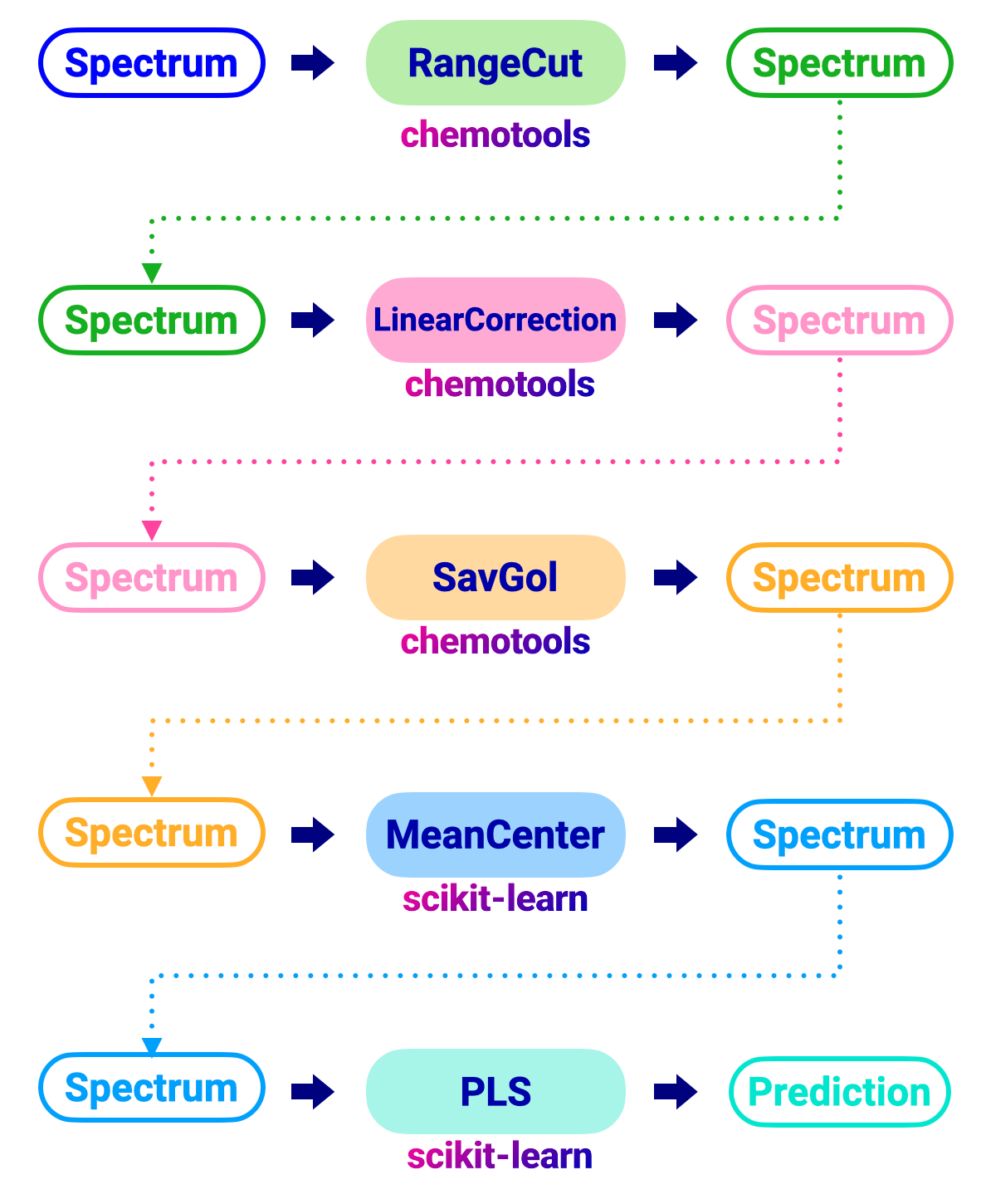
El código para realizar este flujo de trabajo se vería así:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.preprocessing import StandardScaler
# Range Cut
# Define the Range Cut
range_cut = RangeCut(start=950, end=1550, wavenumbers=wavenumbers)
# Fit and apply Range Cut
spectra_cut = range_cut.fit_transform(spectra)
# Linear Correction
# Define the Linear Correction
linear_correction = LinearCorrection()
# Fit and apply Linear Correction
spectra_corrected = linear_correction.fit_transform(spectra_cut)
# Savitzky-Golay
# Define the Savitzky-Golay
savitzky_golay = SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1)
# Fit and apply Savitzky-Golay
spectra_derivate = savitzky_golay.fit_transform(spectra_corrected)
# Mean Centering (Standard Scaler)
# Define the Standard Scaler
standard_scaler = StandardScaler(with_mean=True, with_std=False)
# Fit and apply Standard Scaler
spectra_centered = standard_scaler.fit_transform(spectra_derivate)
# PLS regression
# Define the PLS regression
pls = PLSRegression(n_components=2, scale=False)
# Fit the model
pls.fit(spectra_centered, reference)
# Apply model to make predictions
prediction = pls.predict(spectra_centered)
Este es un flujo de trabajo tedioso y propenso a errores, especialmente cuando el número de pasos de preprocesamiento aumenta. Además, persistir el modelo y desplegarlo en un entorno de producción no es sencillo, ya que cada paso de preprocesamiento necesita ser persistido y desplegado individualmente.
Flujo de pipeline#
En un flujo de pipeline, podemos combinar todos los pasos de preprocesamiento en un único objeto. Esto simplifica el flujo de trabajo y reduce el riesgo de errores. La figura a continuación muestra el mismo flujo de trabajo que antes, pero usando un pipeline:

Un esquema del código para realizar el pipeline se muestra en la imagen a continuación:

El código para realizar el pipeline se muestra a continuación:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
# Fit the model
pipeline.fit(spectra, reference)
# Apply model to make predictions
prediction = pipeline.predict(spectra)
Ahora es posible visualizar el pipeline y los diferentes pasos de preprocesamiento que se aplican a los espectros.
Pipeline(steps=[('rangecut', RangeCut(end=1550, start=950)),
('linearcorrection', LinearCorrection()),
('savitzkygolay',
SavitzkyGolay(polynomial_order=2, window_size=21)),
('standardscaler', StandardScaler(with_std=False)),
('plsregression', PLSRegression(scale=False))])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('rangecut', RangeCut(end=1550, start=950)),
('linearcorrection', LinearCorrection()),
('savitzkygolay',
SavitzkyGolay(polynomial_order=2, window_size=21)),
('standardscaler', StandardScaler(with_std=False)),
('plsregression', PLSRegression(scale=False))])RangeCut(end=1550, start=950)
LinearCorrection()
SavitzkyGolay(polynomial_order=2, window_size=21)
StandardScaler(with_std=False)
PLSRegression(scale=False)
Nota
Observe que en el flujo de trabajo tradicional, los diferentes objetos de preprocesamiento tenían que ser persistidos individualmente. En el flujo de trabajo de pipeline, todo el pipeline puede ser persistido y desplegado en un entorno de producción. Consulte la sección Persistiendo tus modelos para más información.