Persistiendo tus modelos#
Anteriormente, vimos cómo usar chemotools en combinación con scikit-learn para preprocesar tus datos y hacer predicciones. Sin embargo, en un escenario del mundo real, nos gustaría persistir nuestros pipelines entrenados (ajustados) para desplegarlos en un entorno de producción. En esta sección, mostraremos dos formas de persistir nuestros modelos:
Usando
pickleUsando
joblib
Una vista general del flujo de trabajo se muestra en la imagen de abajo:
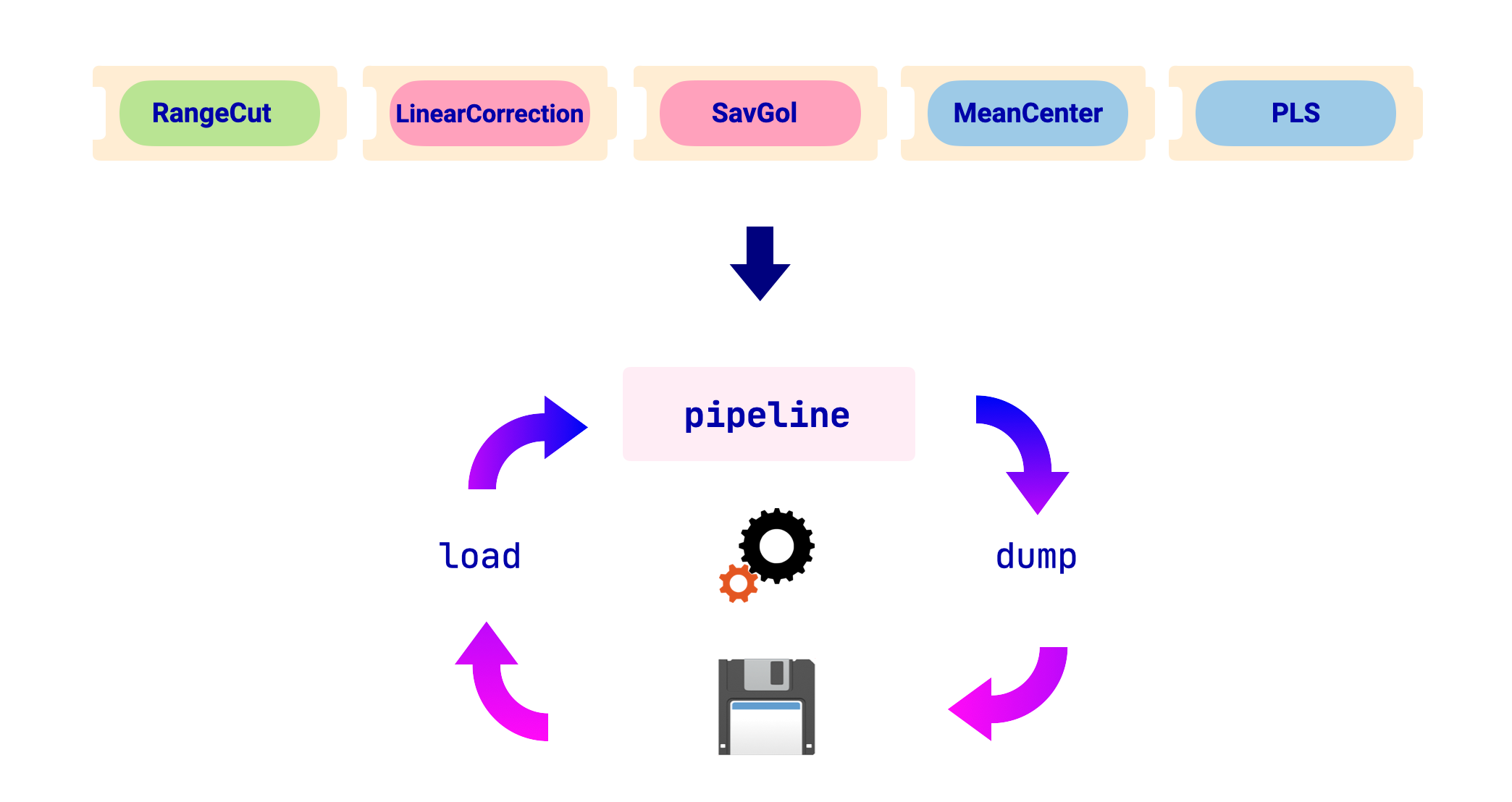
Para esta sección, usaremos el siguiente pipeline ajustado como ejemplo:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
# Fit the model
pipeline.fit(spectra, reference)
Usando pickle#
pickle es un módulo de Python que implementa un protocolo binario para serializar y deserializar una estructura de objetos de Python. Es un módulo estándar que viene con la instalación de Python. El siguiente código muestra cómo persistir un modelo de scikit-learn usando pickle:
Nota
Observa que el módulo pickle no es seguro contra datos erróneos o construidos maliciosamente. Nunca deserialices datos recibidos de una fuente no confiable o no autenticada.
import pickle
# persist model
filename = 'model.pkl'
with open(filename, 'wb') as file:
pickle.dump(pipeline, file)
# load model
with open(filename, 'rb') as file:
pipeline = pickle.load(file)
Usando joblib#
joblib es un módulo de Python que proporciona utilidades para guardar y cargar objetos de Python que hacen uso de estructuras de datos de NumPy, eficientemente. No es parte de la instalación estándar de Python, pero puede instalarse usando pip. El siguiente código muestra cómo persistir un modelo de scikit-learn usando joblib:
from joblib import dump, load
# persist model
filename = 'model.joblib'
with open(filename, 'wb') as file:
dump(pipeline, file)
# load model
with open(filename, 'rb') as file:
pipeline = load(file)