Inspeccionando tus modelos#
El módulo chemotools.inspector proporciona una interfaz unificada para el diagnóstico de modelos. En lugar de crear manualmente gráficos separados para puntuaciones, cargas y valores atípicos, el Inspector genera un conjunto completo de diagnósticos con una sola llamada de método.
Todos los inspectores comparten la misma API, lo que hace intuitivo su uso con diferentes tipos de modelos (PCA, PLS, etc.). Los inspectores soportan múltiples conjuntos de datos (entrenamiento, prueba, validación) y ofrecen amplias opciones de personalización para colores, anotaciones y selección de componentes. Una visión general abstracta de los inspectores se muestra en la Figura a continuación.
Advertencia
El módulo inspector es experimental y está en desarrollo activo. La API puede cambiar en versiones futuras. ¡Agradecemos tus comentarios! Por favor reporta problemas o sugerencias en: paucablop/chemotools#issues
¿Por qué usar el Inspector?#
Reduce el código repetitivo, haz tus flujos de modelos más legibles y asegúrate de comprender completamente tus modelos:
Diagnósticos en una línea: Genera todos los gráficos estándar (Puntuaciones, Cargas, Varianza, Valores atípicos) con
.inspect().Interfaz unificada: API consistente para modelos PCA y PLS.
Soporte multi-conjunto de datos: Compara fácilmente conjuntos de Entrenamiento, Prueba y Validación en los mismos gráficos.
Comparación de espectros: Compara espectros crudos vs preprocesados con
.inspect_spectra().Visualización del preprocesamiento: Recorre cada paso del pipeline y observa su efecto en tus datos con
PreprocessingInspector.Acceso a datos: Extrae puntuaciones, cargas y coeficientes para análisis personalizados.
Interactivo y listo para publicación: Devuelve figuras matplotlib estándar que pueden personalizarse aún más.
Uso básico#
Actualmente, chemotools soporta inspectores para:
Preprocesamiento:
PreprocessingInspectorPCA:
PCAInspectorRegresión PLS:
PLSRegressionInspector
Para el ejemplo, carguemos algunos datos y entrenemos un modelo PCA y un modelo de regresión PLS.
from sklearn.cross_decomposition import PLSRegression
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from chemotools.datasets import load_fermentation_train
from chemotools.derivative import SavitzkyGolay
from chemotools.feature_selection import RangeCut
from chemotools.inspector import PCAInspector, PLSRegressionInspector, PreprocessingInspector
# 1. Load Data
X, y = load_fermentation_train()
wn = X.columns
# 2. Fit the PCA Model
pca = make_pipeline(
RangeCut(start=900, end=1400, wavenumbers=wn),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=0),
StandardScaler(with_std=False),
PCA(n_components=3),
)
pca.fit(X)
# 3. Fit the PLS regression model
pls = make_pipeline(
RangeCut(start=900, end=1400, wavenumbers=wn),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
PLSRegression(n_components=3, scale=False),
)
pls.fit(X, y)
Ahora que hemos entrenado los modelos, podemos inspeccionarlos usando inspector. El núcleo del módulo es el método .inspect(), compartido por todos los inspectores.
Nota
El método inspect() devuelve un diccionario de objetos matplotlib.figure.Figure, permitiéndote guardarlos o modificarlos individualmente.
Inspeccionando pasos de preprocesamiento#
El PreprocessingInspector te permite visualizar el efecto acumulativo de cada paso de preprocesamiento en un pipeline. En lugar de inspeccionar el modelo final, se centra en cómo cambian tus datos a través de cada transformación.
Usando el mismo pipeline de PCA que definimos arriba, podemos inspeccionar cómo cada paso de preprocesamiento transforma los datos:
# Inspect the preprocessing steps of the PCA pipeline
inspector = PreprocessingInspector(pca, X_train=X, y_train=y, x_axis=wn)
figures = inspector.inspect()
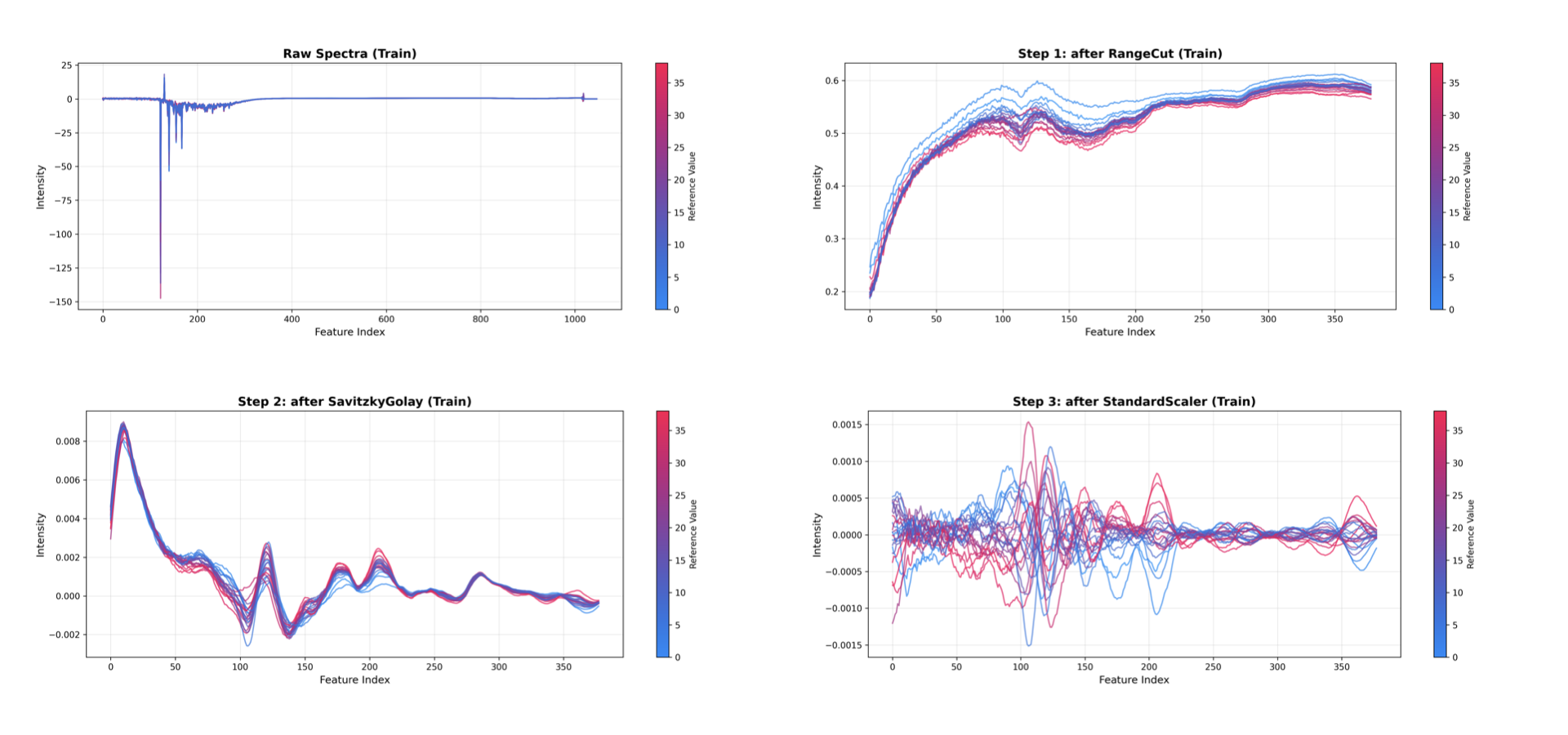
Esto genera un gráfico por cada paso de preprocesamiento, mostrando los datos sin procesar seguidos del resultado acumulado después de cada transformación:
Espectros originales: Los datos de entrada originales.
Después de RangeCut: Los datos tras seleccionar la región espectral de interés.
Después de SavitzkyGolay: Los datos suavizados.
Después de StandardScaler: Los datos centrados en la media.
Los pasos del modelo (p. ej., PCA, PLS) se excluyen automáticamente de la visualización.
El PreprocessingInspector también admite la comparación de múltiples conjuntos de datos. Puedes superponer datos de entrenamiento, prueba y validación para verificar que el preprocesamiento se comporte de forma consistente entre los distintos conjuntos de datos:
from sklearn.model_selection import train_test_split
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0
)
# Initialize the inspector with both train and test data
inspector = PreprocessingInspector(
pca,
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
x_axis=wn,
)
figures = inspector.inspect(dataset=['train', 'test'])
Nota
El PreprocessingInspector también proporciona el método inspect_spectra() para una comparación rápida datos crudos vs. totalmente preprocesados, y un método summary() que devuelve una dataclass tipada con información del pipeline.
Inspeccionando modelos PCA#
A continuación, echamos un vistazo al modelo PCA.
# Inspect the PCA model
inspector = PCAInspector(pca, X_train=X, y_train=y, x_axis=wn)
figures = inspector.inspect()
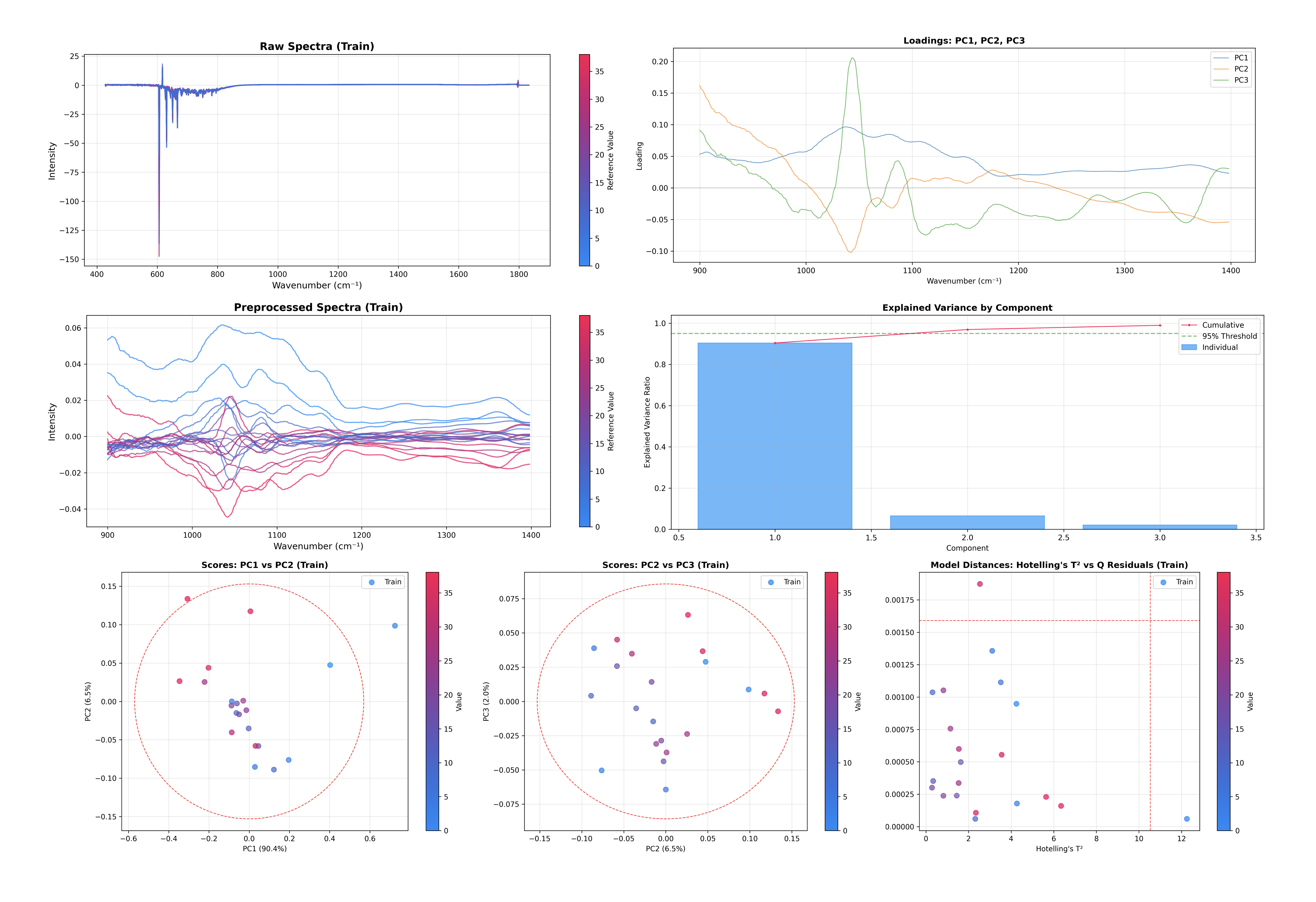
Este único comando genera y muestra varios gráficos de diagnóstico clave:
Varianza explicada: Te ayuda a decidir si tienes suficientes componentes.
Gráfico de puntuaciones: Visualiza el espacio de muestras (PC1 vs PC2, PC2 vs PC3).
Gráfico de cargas: Visualiza el espacio de características (lo que el modelo está observando).
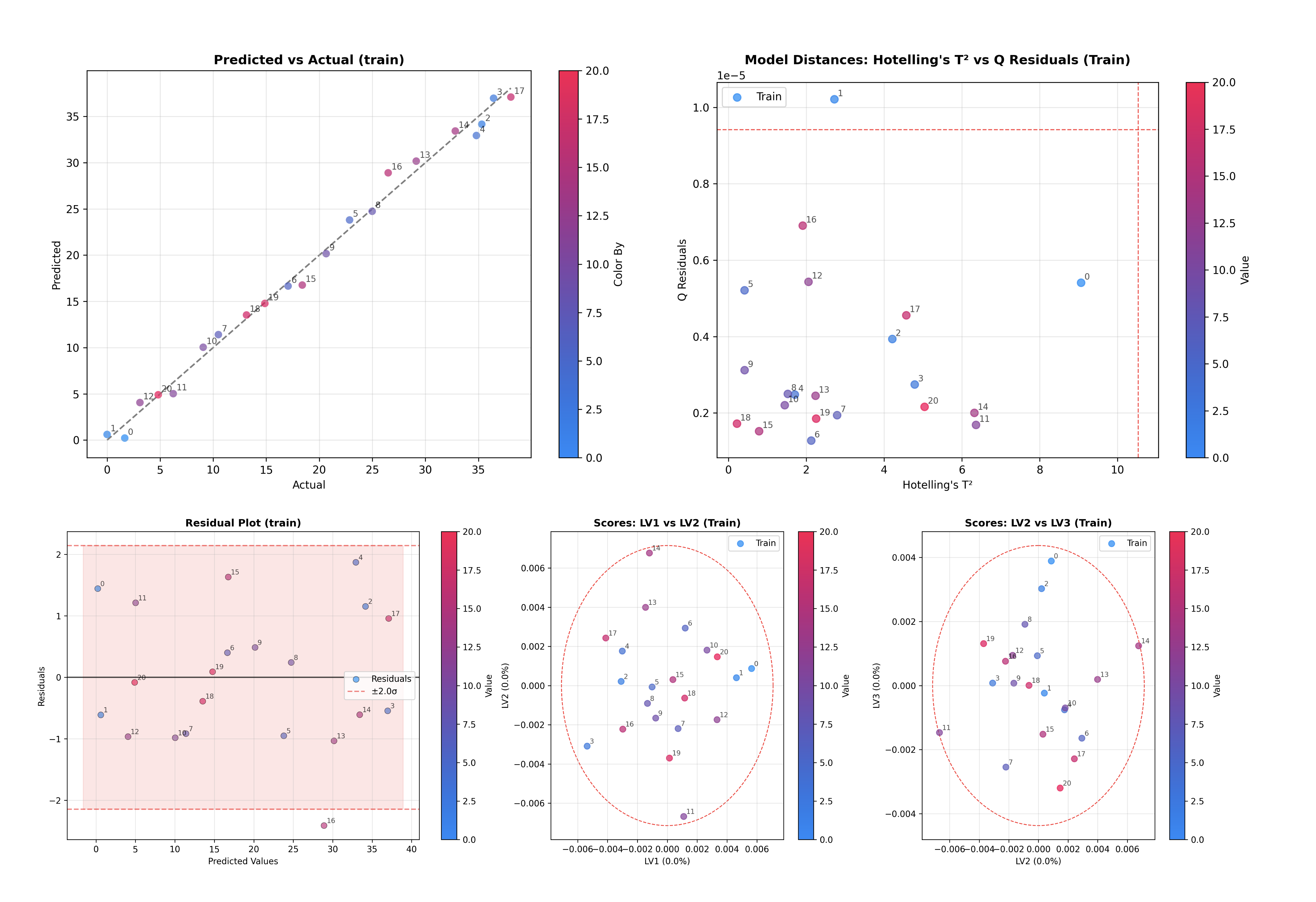
Detección de valores atípicos: Gráfico de T² de Hotelling vs Residuos Q.
Inspeccionando modelos de regresión PLS#
El inspector de regresión PLS comparte la misma API que PCAInspector, lo que facilita cambiar entre ellos.
# Inspect the PLS Regression model
inspector = PLSRegressionInspector(pls, X_train=X, y_train=y, x_axis=wn)
figures = inspector.inspect()
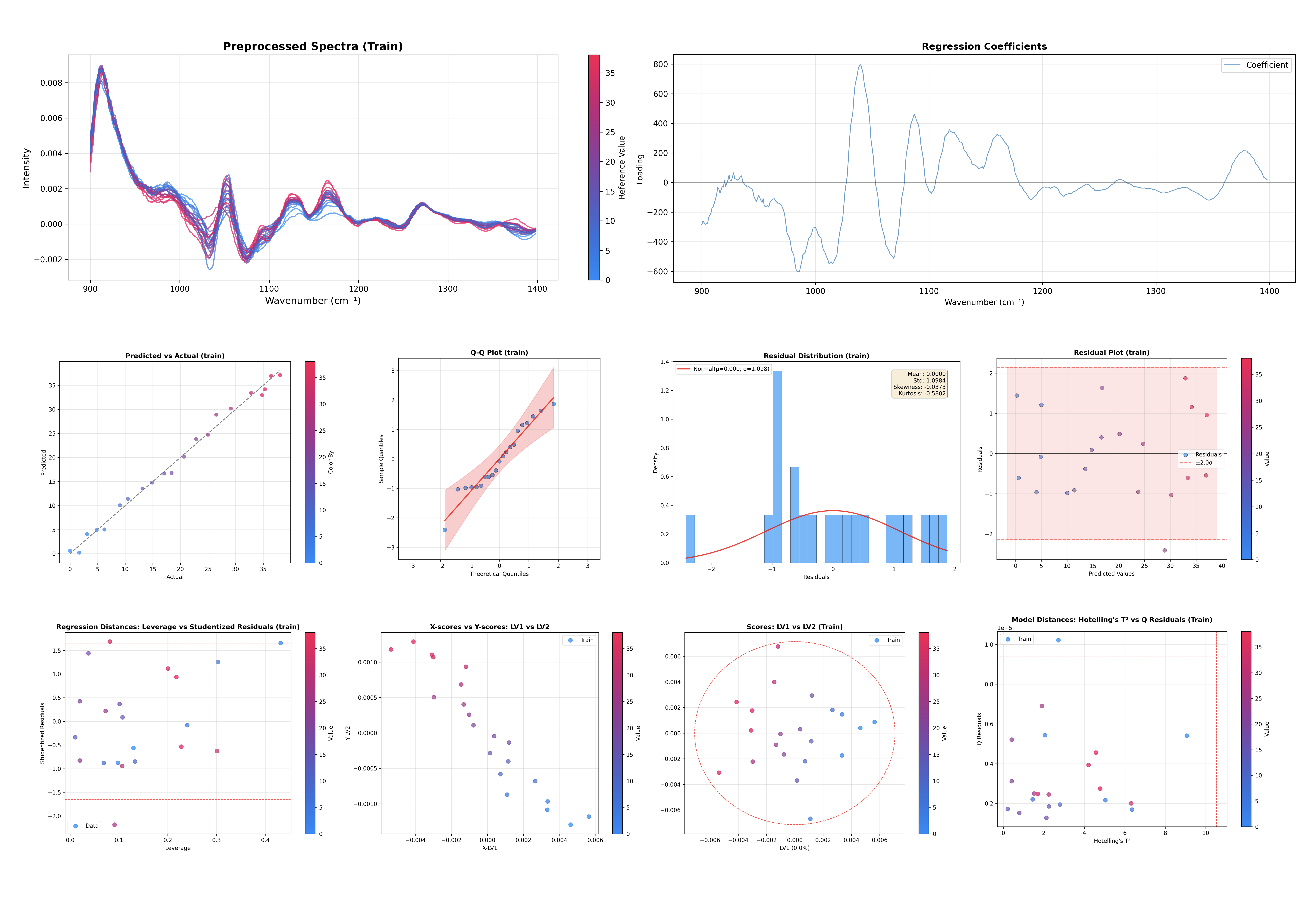
Este comando genera gráficos de diagnóstico adaptados para regresión PLS:
Varianza explicada: Para el espacio X y el espacio Y.
Gráfico de puntuaciones: Visualiza el espacio de muestras (LV1 vs LV2).
Puntuaciones X vs Puntuaciones Y: Correlación entre variables latentes.
Gráficos de cargas: Cargas X, pesos X y rotaciones X.
Coeficientes de regresión: Importancia de características para predicción.
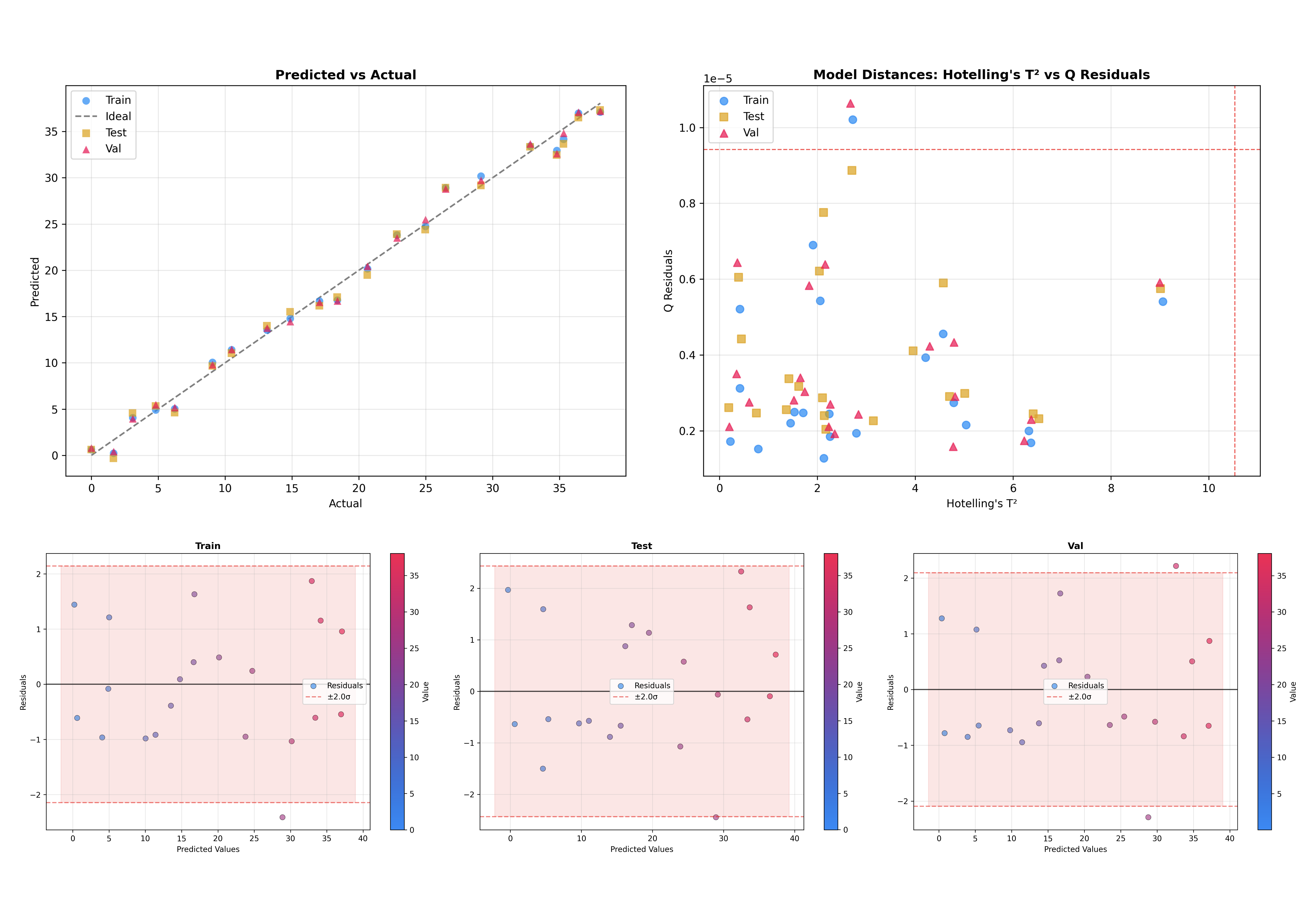
Detección de valores atípicos: Gráfico de T² de Hotelling vs Residuos Q.
Apalancamiento vs Residuos Studentizados: Detección de observaciones influyentes.
Residuos Q vs Residuos Y: Diagnósticos combinados de ajuste del modelo.
Predicho vs Real: Evalúa el rendimiento de la regresión.
Gráfico de residuos Y: Identifica patrones en los errores de predicción.
Gráfico Q-Q: Verifica la normalidad de los residuos.
Distribución de residuos: Histograma de errores de predicción.
Inspeccionando espectros#
Cuando tu modelo incluye pasos de preprocesamiento (ej., un Pipeline de sklearn), puedes comparar los espectros crudos y preprocesados usando el método .inspect_spectra():
# Compare raw vs preprocessed spectra
spectra_figures = inspector.inspect_spectra()
Esto genera dos gráficos:
Espectros crudos: Datos de entrada originales antes de cualquier transformación.
Espectros preprocesados: Datos después de todos los pasos de preprocesamiento (antes del modelo).
Esto es particularmente útil en flujos de trabajo de espectroscopía para verificar que los pasos de preprocesamiento (corrección de línea base, derivadas, normalización) están funcionando como se esperaba.
Nota
El método inspect_spectra() solo está disponible cuando el modelo es un Pipeline con pasos de preprocesamiento. También es llamado automáticamente por .inspect() cuando existe preprocesamiento.
Personalizando la inspección#
El método inspect() es altamente personalizable. Puedes controlar qué componentes graficar, cómo colorear las muestras y qué conjuntos de datos incluir.
Seleccionando componentes#
Puedes especificar qué componentes visualizar en los gráficos de puntuaciones y cargas.
# Plot LV2 vs LV3 for scores, and the first 2 components for loadings
inspector.inspect(
components_scores=(1, 2),
loadings_components=[0, 1]
)
El parámetro components_scores acepta:
int: Grafica los primeros N componentes contra el índice de muestra
tuple (i, j): Grafica el componente i vs el componente j
list: Múltiples especificaciones, ej.,
[(0, 1), (1, 2)]
Colores y anotaciones#
Por defecto, los gráficos se colorean según la variable objetivo y (si se proporciona). Puedes personalizar este comportamiento usando los parámetros color_by y annotate_by.
# Color by y and annotate by sample index
inspector.inspect(color_by='y', annotate_by='sample_index')
Ambos parámetros aceptan:
'y': Colorear/anotar por la variable objetivo.'sample_index': Colorear/anotar por índices de muestra.array-like: Valores personalizados de la misma longitud que el número de muestras.
dict: Mapea nombres de conjuntos de datos a arrays para gráficos multi-conjunto, ej.,
{'train': array1, 'test': array2}.
Modo de color#
El parámetro color_mode controla cómo se aplican los colores:
# Use categorical coloring (discrete colors for each unique value)
inspector.inspect(color_by='y', color_mode='categorical')
# Use continuous coloring (gradient based on values) - default
inspector.inspect(color_by='y', color_mode='continuous')
Comparando conjuntos de datos#
Otra característica útil es la capacidad de superponer múltiples conjuntos de datos. Esto es crítico para verificar qué tan bien generaliza el modelo a datos no vistos.
# Initialize inspector with train, test, and validation data
inspector = PLSRegressionInspector(
pls,
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
X_val=X_val,
y_val=y_val,
x_axis=wn,
)
# Inspect all datasets together
figures = inspector.inspect(dataset=['train', 'test', 'val'])
Esto producirá gráficos donde las muestras de entrenamiento, prueba y validación se visualizan juntas, facilitando detectar cambios de dominio o sobreajuste.
PLS multi-salida#
Para modelos PLS multi-salida (múltiples variables objetivo), usa el parámetro target_index para seleccionar qué objetivo inspeccionar:
# Inspect the second target variable (index 1)
inspector.inspect(target_index=1)
Configuración de gráficos#
Para un control detallado sobre los tamaños de figura, usa el parámetro plot_config o pasa argumentos de tamaño directamente:
from chemotools.inspector import InspectorPlotConfig
# Using plot_config
config = InspectorPlotConfig(
scores_figsize=(10, 8),
loadings_figsize=(12, 4),
variance_figsize=(8, 6),
)
inspector.inspect(plot_config=config)
# Or pass sizes directly as kwargs
inspector.inspect(scores_figsize=(10, 8))
Trabajando con figuras#
El método inspect() devuelve un diccionario de objetos matplotlib.figure.Figure. Esto te permite acceder a gráficos individuales, personalizarlos aún más o guardarlos en archivos.
Accediendo a gráficos individuales#
Cada figura en el diccionario devuelto tiene una clave descriptiva:
# Get all figures
figures = inspector.inspect()
# See available figure keys
print(figures.keys())
# dict_keys(['variance_x', 'variance_y', 'loadings_x', 'loadings_weights',
# 'loadings_rotations', 'regression_coefficients', 'scores_1',
# 'scores_2', 'x_vs_y_scores_1', 'distances_hotelling_q', ...])
# Access a specific figure
scores_fig = figures['scores_1']
loadings_fig = figures['loadings_x']
Las claves de figura disponibles dependen del tipo de inspector:
PCAInspector:
variance: Gráfico de varianza explicadaloadings: Gráfico de cargasscores_1,scores_2, …: Gráficos de puntuacionesdistances: T² de Hotelling vs Residuos Q
PLSRegressionInspector:
variance_x,variance_y: Gráficos de varianza explicadaloadings_x,loadings_weights,loadings_rotations: Loadings plotsregression_coefficients: Coefficient plotscores_1,scores_2, …: Gráficos de puntuaciones Xx_vs_y_scores_1,x_vs_y_scores_2, …: Gráficos de puntuaciones X vs Ydistances_hotelling_q: T² de Hotelling vs residuos Qdistances_leverage_studentized: Apalancamiento vs residuos tipificadosdistances_q_y_residuals: Residuos Q vs residuos Ypredicted_vs_actual: Gráfico de predicción vs valor realresiduals: Gráfico de residuos Yqq_plot: Gráfico Q-Qresidual_distribution: Histograma de residuosraw_spectra,preprocessed_spectra: Gráficos de espectros (si existe preprocesamiento)
Guardar figuras#
Puede guardar figuras individuales o todas las figuras a la vez:
# Save a single figure
figures['scores_1'].savefig('scores_plot.png', dpi=300, bbox_inches='tight')
# Save as PDF for publications
figures['loadings_x'].savefig('loadings.pdf', bbox_inches='tight')
# Save all figures to a directory
import os
output_dir = 'model_diagnostics'
os.makedirs(output_dir, exist_ok=True)
for name, fig in figures.items():
fig.savefig(f'{output_dir}/{name}.png', dpi=300, bbox_inches='tight')
Personalización de figuras#
Dado que las figuras son objetos estándar de matplotlib, puede modificarlas después de crearlas:
# Get a figure and customize it
fig = figures['scores_1']
ax = fig.axes[0]
# Modify title, labels, etc.
ax.set_title('My Custom Title', fontsize=14, fontweight='bold')
ax.set_xlabel('Latent Variable 1')
ax.set_ylabel('Latent Variable 2')
# Add annotations, lines, etc.
ax.axhline(y=0, color='gray', linestyle='--', alpha=0.5)
ax.axvline(x=0, color='gray', linestyle='--', alpha=0.5)
# Update the figure
fig.tight_layout()
Acceso a los datos del modelo#
Además de la generación de gráficos, los inspectores proporcionan métodos para extraer datos subyacentes para análisis personalizados.
Inspector de PCA#
inspector = PCAInspector(pca, X_train=X, y_train=y, x_axis=wn)
# Get scores for a dataset
scores = inspector.get_scores('train') # Shape: (n_samples, n_components)
# Get loadings (optionally select components)
loadings = inspector.get_loadings() # All components
loadings = inspector.get_loadings([0, 1]) # First two components
# Get explained variance ratio
variance = inspector.get_explained_variance_ratio()
Inspector de regresión PLS#
inspector = PLSRegressionInspector(pls, X_train=X, y_train=y, x_axis=wn)
# X-space scores and loadings
x_scores = inspector.get_x_scores('train')
x_loadings = inspector.get_x_loadings()
x_weights = inspector.get_x_weights()
x_rotations = inspector.get_x_rotations()
# Y-space scores
y_scores = inspector.get_y_scores('train')
# Regression coefficients
coefficients = inspector.get_regression_coefficients()
# Explained variance in X and Y space
x_variance = inspector.get_explained_x_variance_ratio()
y_variance = inspector.get_explained_y_variance_ratio()
Resúmenes del modelo#
Los inspectores proporcionan estadísticas resumidas de los modelos mediante el método .summary(). Este devuelve un objeto dataclass con un método .to_dict() para facilitar su conversión a diccionarios.
Resumen del modelo#
# Get model summary
summary = inspector.summary()
# Access as object attributes
print(summary.model_type) # 'PLSRegression'
print(summary.n_components) # 3
print(summary.n_features) # 1047
# Convert to dictionary
summary.to_dict()
El método .to_dict() devuelve:
{
'model_type': 'PLSRegression',
'has_preprocessing': True,
'n_features': 1047,
'n_components': 3,
'n_samples': {'train': 21, 'test': 21, 'val': 21},
'preprocessing_steps': [
{'step': 1, 'name': 'rangecut', 'type': 'RangeCut'},
{'step': 2, 'name': 'savitzkygolay', 'type': 'SavitzkyGolay'}
],
'hotelling_t2_limit': 12.34,
'q_residuals_limit': 0.56,
'train': {'rmse': 1.07, 'r2': 0.99, 'bias': 0.01},
'test': {'rmse': 1.21, 'r2': 0.99, 'bias': -0.02},
...
}
Métricas de regresión#
Para modelos de regresión PLS, puede acceder directamente a las métricas de regresión desde el objeto de resumen:
summary = inspector.summary()
# Access metrics for specific datasets
print(summary.train.rmse) # 1.07
print(summary.train.r2) # 0.99
print(summary.test.bias) # -0.02
La propiedad .metrics proporciona una estructura optimizada para pandas.DataFrame:
import pandas as pd
# Get metrics in DataFrame-friendly format
pd.DataFrame(inspector.summary().metrics).T
| train | test | val | |
|---|---|---|---|
| rmse | 1.930431e+00 | 2.717529 | 13.107082 |
| r2 | 9.746810e-01 | 0.949825 | -0.167189 |
| bias | -8.035900e-16 | 1.882106 | -12.964854 |
Véase también#
Fundamentos de graficación: Para un control de bajo nivel sobre gráficos individuales.
Valores atípicos: Para detalles sobre las estadísticas de detección de valores atípicos.