Optimizar el modelo#
Al construir un modelo quimiométrico, los analistas necesitan tomar varias decisiones sobre hiperparámetros que pueden afectar significativamente el rendimiento del modelo. Los hiperparámetros son aquellos parámetros que se establecen antes de entrenar el modelo. Algunos hiperparámetros comunes son:
¿Cuántos componentes debería usar el modelo?
¿Cuál es la mejor longitud de filtro para un filtro de Savitzky-Golay?
¿Qué orden polinomial funciona mejor?
Para responder a estas preguntas, se prueban y evalúan diferentes combinaciones de hiperparámetros, típicamente usando validación cruzada, para encontrar aquellas que producen el modelo de mejor rendimiento.
En esta sección, investigaremos diferentes opciones para optimizar estas elecciones usando chemotools y las opciones de optimización de modelos de Scikit-Learn como GridSearchCV o RandomSearchCV, que ayudarán a buscar en el espacio de hiperparámetros sistemáticamente y seleccionar los mejores hiperparámetros.
Dos excelentes recursos avanzados para la optimización de hiperparámetros se muestran a continuación por los compañeros de Probabl..
|
|


Optimización de hiperparámetros#
Como ejemplo, optimizaremos los hiperparámetros en el pipeline representado en la imagen de abajo.

El pipeline se puede crear usando el código mostrado a continuación:
from chemotools.feature_selection import RangeCut
from chemotools.baseline import LinearCorrection
from chemotools.derivative import SavitzkyGolay
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# Define the pipeline
pipeline = make_pipeline(
RangeCut(start=950, end=1550, wavenumbers=wavenumbers),
LinearCorrection(),
SavitzkyGolay(window_size=21, polynomial_order=2, derivate_order=1),
StandardScaler(with_mean=True, with_std=False),
PLSRegression(n_components=2, scale=False)
)
- Todos los métodos de optimización de hiperparámetros siguen los tres pasos siguientes:
Todos exploran el espacio de hiperparámetros para encontrar un conjunto óptimo de hiperparámetros.
Todos usan validación cruzada para evaluar el rendimiento de cada conjunto de hiperparámetros.
Nota
La principal diferencia entre estos métodos es cómo exploran el espacio de hiperparámetros. Por ejemplo, GridSearchCV explora el espacio de hiperparámetros sistemáticamente, mientras que RandomSearchCV muestrea un número fijo de combinaciones aleatorias del espacio de hiperparámetros.
El primer paso es definir el espacio de hiperparámetros. En nuestro caso nos gustaría evaluar los siguientes hiperparámetros: - El número de componentes en el modelo de regresión PLS (n_components) - El tamaño de ventana del filtro Savitzky-Golay (window_size) - El orden polinomial del filtro Savitzky-Golay (polynomial_order) - El orden de la derivada del filtro Savitzky-Golay (derivate_order)
Para definir el espacio de hiperparámetros, podemos definir la cuadrícula de hiperparámetros como un diccionario, donde las claves son los nombres de los hiperparámetros y los valores son listas de valores posibles para cada hiperparámetro. El código para definir el espacio de hiperparámetros se muestra a continuación:
# Define the hyperparameter space
param_grid = {
'plsregression__n_components': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'savitzkygolay__window_size': [5, 11, 21],
'savitzkygolay__polynomial_order': [2, 3],
'savitzkygolay__derivate_order': [0, 1]
}
El siguiente paso es definir las posiciones de las muestras en el espacio de hiperparámetros. Investigaremos diferentes estrategias.
GridSearchCV#
GridSearchCV es un método que realiza una búsqueda exhaustiva sobre una cuadrícula de parámetros especificada. Evalúa todas las combinaciones posibles de hiperparámetros en la cuadrícula y selecciona la que produce el mejor rendimiento basándose en la validación cruzada. Este método es útil cuando el espacio de hiperparámetros es pequeño y está bien definido. Una representación visual del proceso de GridSearchCV se muestra a continuación:
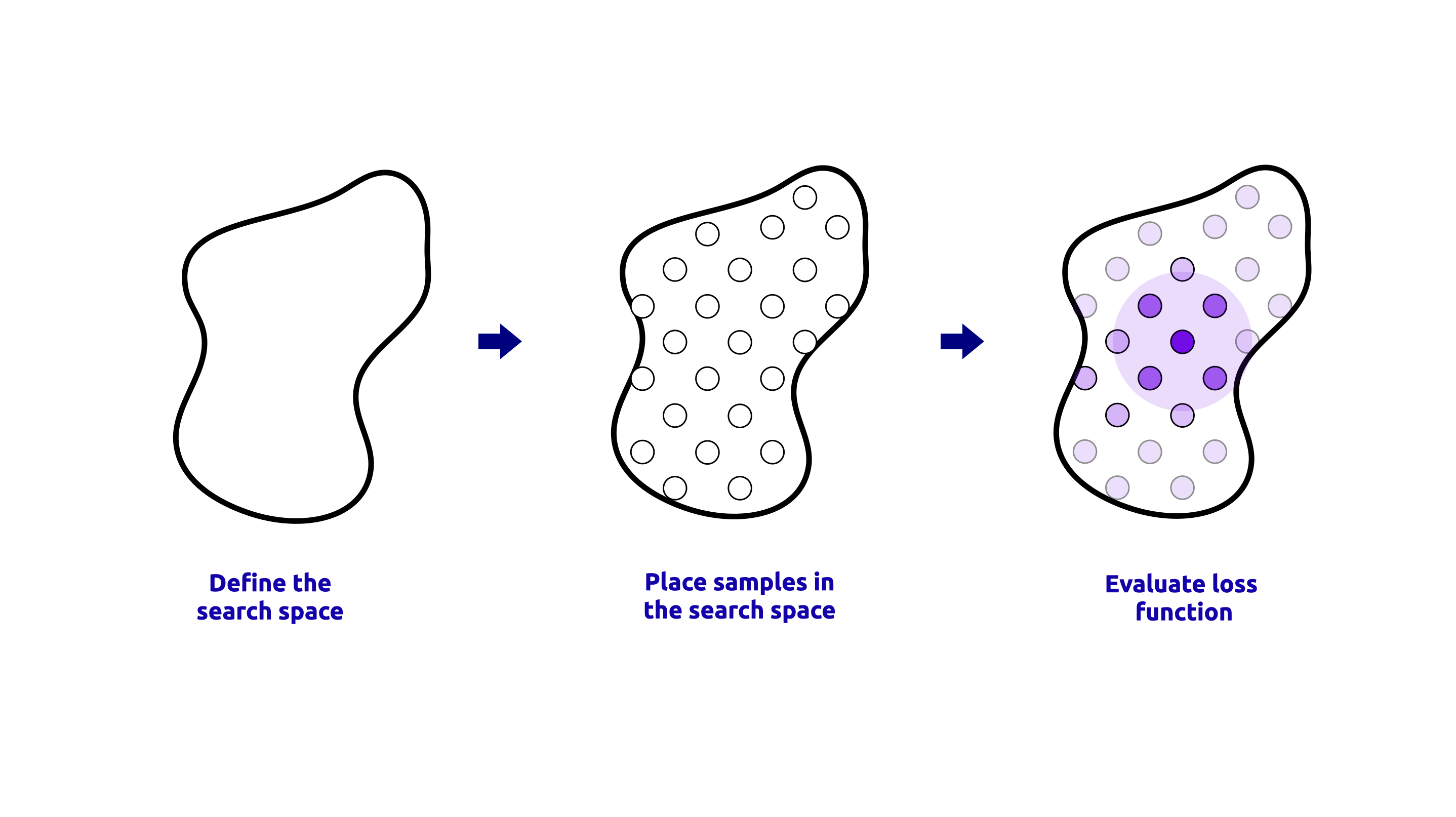
El código para realizar GridSearchCV se muestra a continuación:
from sklearn.model_selection import GridSearchCV
# Define the GridSearchCV
grid_search = GridSearchCV(
pipeline,
param_grid=param_grid,
scoring='neg_mean_squared_error',
cv=5,
n_jobs=-1
)
# Fit the model
grid_search.fit(spectra, reference)
# Get the best hyperparameters
best_params = grid_search.best_params_
print("Best hyperparameters:", best_params)
# Get the best score
best_score = grid_search.best_score_
print("Best score:", best_score)
# Get the best estimator
best_estimator = grid_search.best_estimator_
print("Best estimator:", best_estimator)
- Hay algunos parámetros importantes a tener en cuenta en la función
GridSearchCV: scoringespecifica la métrica utilizada para evaluar el rendimiento del modelo. En este caso, estamos usando el error cuadrático medio negativo (MSE) como métrica de puntuación.cvespecifica el número de pliegues de validación cruzada a usar. En este caso, estamos usando validación cruzada de 5 pliegues.n_jobsespecifica el número de trabajos a ejecutar en paralelo. En este caso, estamos usando todos los núcleos disponibles estableciendon_jobs=-1.
Nota
🚀 Aprovechar los múltiples núcleos acelerará el proceso de optimización de hiperparámetros, especialmente cuando el conjunto de datos es grande. ¡Puedes acelerar aún más el proceso almacenando en caché los resultados intermedios usando el parámetro memory en el pipeline, como se muestra en el video anterior!
RandomizedSearchCV#
RandomizedSearchCV es un método que muestrea un número fijo de combinaciones aleatorias del espacio de hiperparámetros y evalúa su rendimiento usando validación cruzada. Este método es útil cuando el espacio de hiperparámetros es grande y está bien definido. Una representación visual del proceso de RandomizedSearchCV se muestra a continuación:
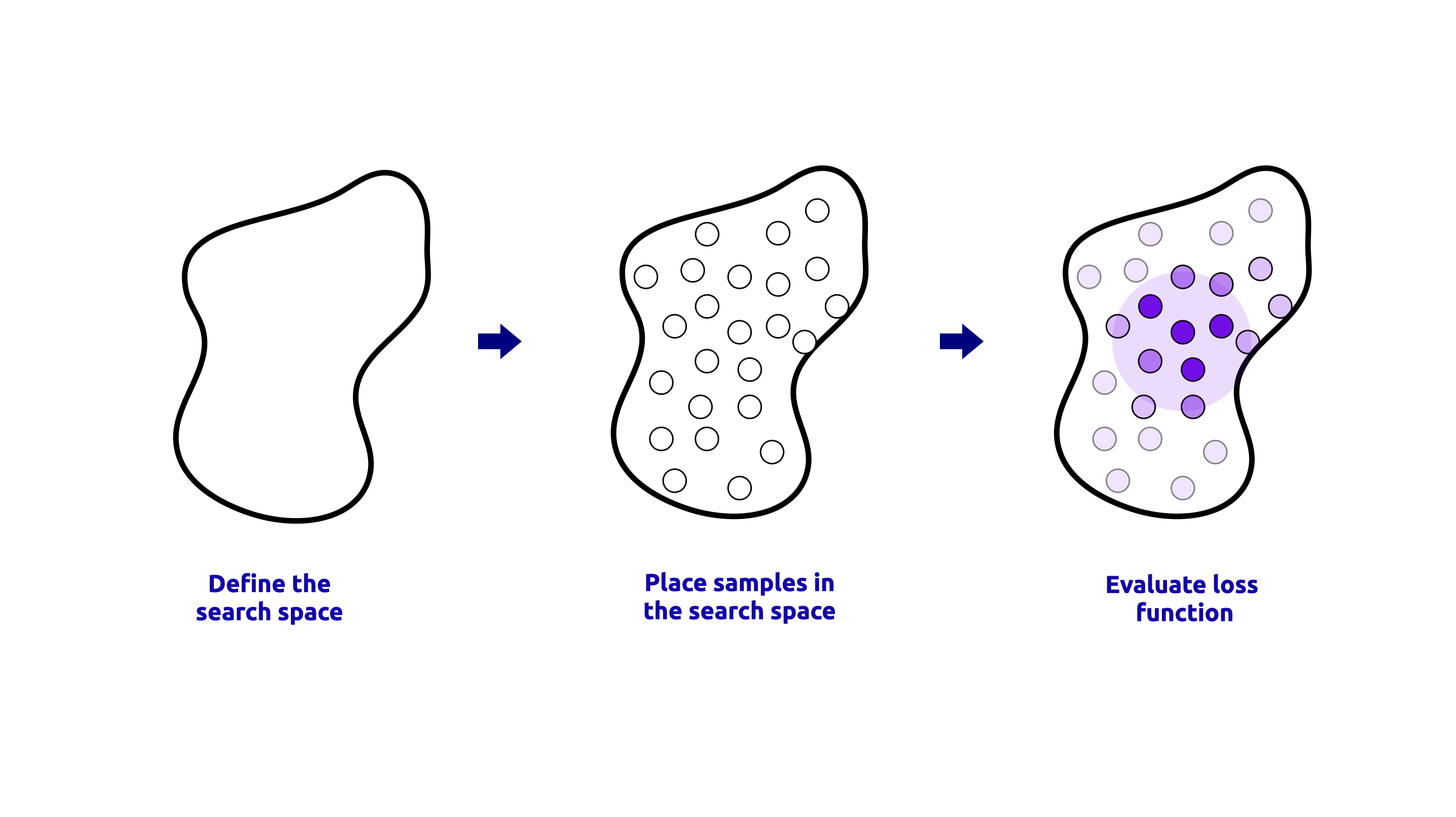
El código para realizar RandomizedSearchCV se muestra a continuación:
from sklearn.model_selection import RandomizedSearchCV
# Define the RandomizedSearchCV
random_search = RandomizedSearchCV(
pipeline,
param_distributions=param_grid,
n_iter=10,
scoring='neg_mean_squared_error',
cv=5,
n_jobs=-1
)
# Fit the model
random_search.fit(spectra, reference)
# Get the best hyperparameters
best_params = random_search.best_params_
print("Best hyperparameters:", best_params)
# Get the best score
best_score = random_search.best_score_
print("Best score:", best_score)
# Get the best estimator
best_estimator = random_search.best_estimator_
print("Best estimator:", best_estimator)
El parámetro n_iter especifica el número de combinaciones aleatorias a muestrear del espacio de hiperparámetros. En este caso, estamos muestreando 10 combinaciones aleatorias. El parámetro param_distributions especifica el espacio de hiperparámetros del cual muestrear. En este caso, estamos usando el mismo espacio de hiperparámetros que en el ejemplo de GridSearchCV. Los parámetros scoring, cv y n_jobs son los mismos que en el ejemplo de GridSearchCV.
Nota
Como se explica en el video anterior, RandomizedSearchCV permite explorar más puntos de datos en el espacio de hiperparámetros, lo que puede llevar a mejores resultados que GridSearchCV, especialmente cuando el espacio de hiperparámetros es grande.