使用 PLS-DA 分类咖啡#
💡注意: 本文档是一个 Jupyter 笔记本。您可以下载源文件并在您的 Jupyter 环境中运行!
引言#
您能品尝出埃塞俄比亚、巴西和越南咖啡的区别吗?
在本教程中,我们将使用光谱学和机器学习来找出三种不同咖啡的产地:
🇪🇹 Ethiopia
🇧🇷 Brazil
🇻🇳 Vietnam
这些光谱是通过衰减全反射中红外光谱(ATR-MIR)从冲泡咖啡中收集的。
在本指南中,我们将逐步创建一个分类模型,该模型可以从光谱特征中区分每种咖啡产地的独特指纹。
所以,拿起您最喜欢的咖啡杯,准备深入数据驱动的发现世界,让我们开始这段芳香之旅。
💡注意: 在我们的数据集中,我们在相同条件下烘焙了所有咖啡,但有一个转折:埃塞俄比亚和巴西咖啡豆被冲泡成意式浓缩咖啡,而越南咖啡则用摩卡壶冲泡 ✨
目标#
在本练习中,我们将构建一个 PLS-DA 模型来分类来自三个不同产地的咖啡样本。
开始之前#
在开始之前,您需要确保已安装以下依赖项:
chemotools
matplotlib
numpy
pandas
scikit-learn
您可以使用以下命令安装它们
pip install chemotools
pip install matplotlib
pip install numpy
pip install pandas
pip install scikit-learn
加载咖啡数据集#
咖啡数据集可以直接从 chemotools.datasets 模块中使用 load_coffee() 函数访问。
[ ]:
from chemotools.datasets import load_coffee
spectra, labels = load_coffee()
load_coffee() 函数返回两个变量:spectra 和 labels:
spectra:一个pandas.DataFrame,包含咖啡样本的光谱,每行代表一个样本。labels:一个pandas.DataFrame,包含每个样本的产地。
💡注意: 如果您有兴趣使用
polars.DataFrame,您可以简单地使用load_coffee(set_output="polars")。
探索、绘图和着色#
在我们深入咖啡数据分析之前,我们将快速检查数据集。让我们先了解数据大小的概况,然后开始我们的分析。
[ ]:
print(f"The spectra dataset has {spectra.shape[0]} samples")
print(f"The spectra dataset has {spectra.shape[1]} features")
The spectra dataset has 60 samples
The spectra dataset has 1841 features
spectra 数据集包含 60 个样本(行)和 1841 个特征(列)。每个样本是一个光谱,每个特征是一个波数。labels 数据集包含每个样本的产地。要分析 labels 数据集,我们可以使用 pandas 的 value_counts() 方法并制作条形图。
[ ]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 3))
labels.value_counts().plot.bar(color=["Violet", "Salmon", "LightBlue"])
ax.set_ylabel("Number of samples")
ax.set_title("Number of samples per class")
Text(0.5, 1.0, 'Number of samples per class')
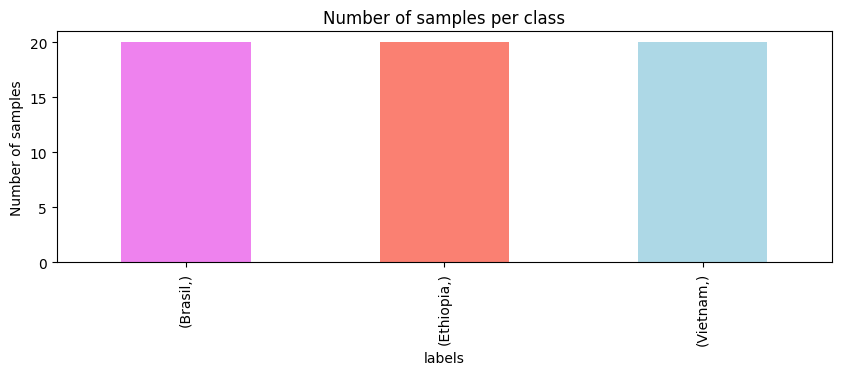
我们有一个平衡的数据集,每个类别有 20 个样本。既然我们对数据有了更好的理解,让我们开始绘制光谱。我们将绘制不同的光谱,并按它们的产地着色。
[ ]:
# define a color dictionary for each origin
color_dict = {
"Brasil": "Violet",
"Ethiopia": "Salmon",
"Vietnam": "LightBlue",
}
fig, ax = plt.subplots(figsize=(10, 3))
for i, row in enumerate(spectra.iterrows()):
ax.plot(row[1].values, color=color_dict[labels.iloc[i].values[0]])
ax.set_xlabel("Wavelength (a.u.)")
ax.set_ylabel("Absorbance (a.u.)")
ax.set_title("Coffee spectra")
Text(0.5, 1.0, 'Coffee spectra')
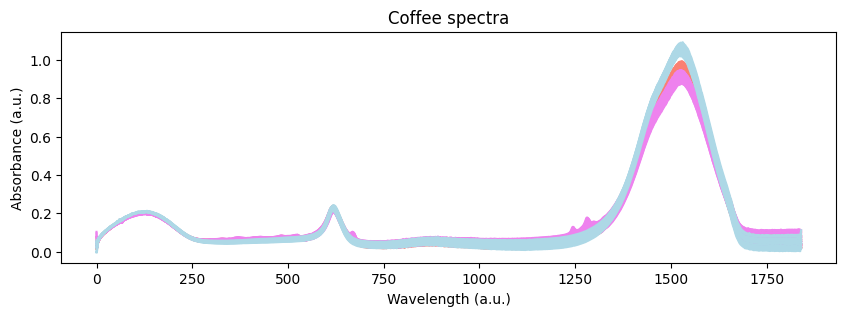
从视觉上看,我们可以看到三种咖啡的光谱存在一些差异。然而,我们需要更深入地了解这些差异的起源。让我们从探索性分析开始。我们可以使用主成分分析(PCA)来降低数据的维度。
为此,我们将首先使用 scikit-learn 的 StandardScaler() 预处理方法对数据进行均值中心化。然后,我们将使用同样来自 scikit-learn 的 PCA() 方法将数据的维度降低到两个主成分。最后,我们将绘制得分图,并根据咖啡的产地为其着色。
💡注意: 使用光谱数据时,我们不想将光谱缩放到单位方差。相反,我们希望将数据均值中心化。这是因为光谱的方差与样品的吸光度有关。如果我们将数据缩放到单位方差,就会丢失关于样品吸光度的信息。我们可以使用
StandardScaler()并将use_std参数设置为False来对数据进行均值中心化。
[ ]:
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# standardize the data
spectra_scaled = StandardScaler(with_std=False).fit_transform(spectra)
# make a PCA object
pca = PCA(n_components=2)
# fit and transform the data
spectra_pca = pca.fit(spectra_scaled).transform(spectra_scaled)
# Make a dataframe with the PCA scores
spectra_pca_df = pd.DataFrame(
data=spectra_pca, columns=["PC1", "PC2"], index=spectra.index
)
# Add the labels to the dataframe
spectra_pca_df = pd.concat([spectra_pca_df, labels], axis=1)
# Plot the PCA scores
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(
spectra_pca_df["PC1"],
spectra_pca_df["PC2"],
c=spectra_pca_df["labels"].map(color_dict),
)
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_title("PCA scores")
Text(0.5, 1.0, 'PCA scores')
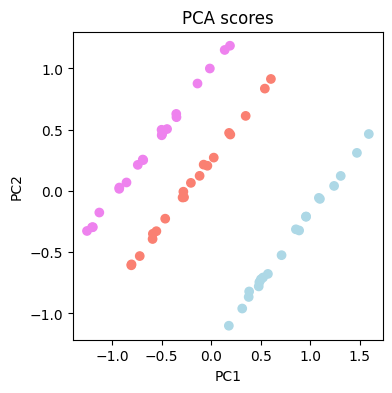
结果显示三种咖啡的光谱之间存在一些差异。
预处理光谱#
预处理的目标是从光谱中去除非化学系统变异,例如基线漂移或散射效应。关于光谱数据预处理已有大量研究,这正是 chemotools 变得非常方便的地方:我们利用这些研究的力量,并使用 scikit-learn 标准将其提供给您。
我们将使用 sklearn.pipeline 中的 make_pipeline() 方法在管道中构建预处理步骤。管道 是按给定顺序应用于数据的一系列步骤。在我们的案例中,我们将应用以下步骤:
标准正态变量(SNV) 以去除散射效应。
导数 以去除加性和乘性散射效应。
范围截取 以选择最相关的波数。
标准化 从数据集中去除均值。
[ ]:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from chemotools.derivative import SavitzkyGolay
from chemotools.feature_selection import RangeCut
from chemotools.scatter import StandardNormalVariate
pipeline = make_pipeline(
StandardNormalVariate(),
SavitzkyGolay(window_size=21, polynomial_order=1),
RangeCut(start=10, end=1350),
StandardScaler(with_std=False),
)
preprocessed_spectra = pipeline.fit_transform(spectra)
💡注意: 这很酷!看到我们如何将化学计量学与
scikit-learn集成吗?StandardNormalVariate、SavitizkyGolay和RangeCut都是在chemotools中实现的预处理技术,而StandardScaler和pipelines是scikit-learn提供的功能。这就是chemotools的强大之处,它被设计为与scikit-learn无缝协作。
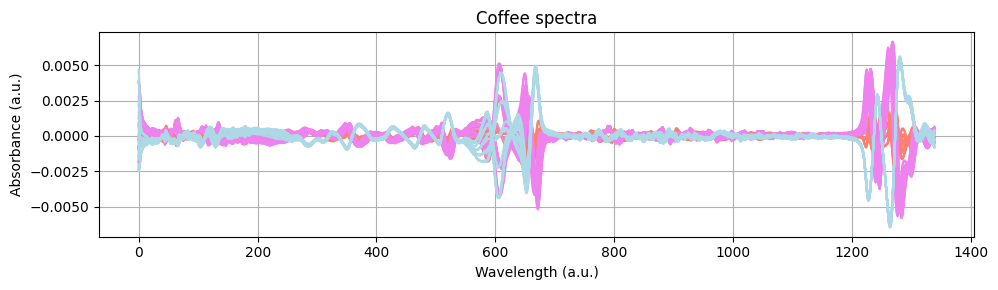
让我们绘制预处理后的光谱,看看预处理步骤的效果。
[ ]:
fig, ax = plt.subplots(figsize=(10, 3))
for i, spectrum in enumerate(preprocessed_spectra):
ax.plot(spectrum, color=color_dict[labels.iloc[i].values[0]])
ax.set_xlabel("Wavelength (a.u.)")
ax.set_ylabel("Absorbance (a.u.)")
ax.set_title("Coffee spectra")
ax.grid()
plt.tight_layout()
plt.show()
构建分类器#
在本节中,我们将深入分类的世界。我们的目标?创建一个分类模型,可以使用咖啡的光谱特征来区分它们的产地。
偏最小二乘判别分析(PLS-DA)是一种用于分类的简单统计技术。PLS-DA 模拟输入变量(光谱数据)和类别标签(咖啡产地)之间的关系,使其能够基于光谱特征以高精度分类新样本。它是复杂数据集中模式识别的强大工具,使其成为我们咖啡产地分类的理想选择。
在我们开始 PLS-DA 算法之前,我们需要将标签编码为数字。我们可以使用 scikit-learn 的 LabelEncoder() 方法来实现。
LabelEncoder() 将为数据集中的每个标签分配一个分类值(0 代表巴西,1 代表埃塞俄比亚,2 代表越南)。
[ ]:
from sklearn.preprocessing import LabelEncoder
# Make Label Encoder
level_encoder = LabelEncoder()
# Fit the Label Encoder
level_encoder.fit(labels.values.ravel())
# Transform the labels
labels_encoded = level_encoder.transform(labels.values.ravel())
既然我们的咖啡产地标签已编码为数值,我们准备训练我们的 PLS-DA 模型。然而,在开始之前,我们将使用 scikit-learn 库中的 train_test_split() 方法将数据分为训练集和测试集。
我们的策略是将数据集的 80% 分配给模型训练,使其能够从光谱数据的不同特征中学习,同时保留剩余的 20% 用于测试。这种划分确保我们可以在未见过的数据上评估模型的性能,这是评估其实际适用性和预测能力的关键步骤。
[ ]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
preprocessed_spectra, labels_encoded, test_size=0.2, random_state=42
)
💡注意: 我们将
random_state参数设置为 42 以确保结果的可重现性。
既然我们有了训练集和测试集,我们可以开始构建我们的 PLS-DA 模型。我们将使用 scikit-learn 的 PLSRegression() 方法。我们将组件数设置为 2,并将 scale 参数设置为 False。这是因为我们已经在预处理步骤中对数据进行了缩放。
[ ]:
from sklearn.cross_decomposition import PLSRegression
# Make a PLSRegression object
pls = PLSRegression(n_components=2, scale=False)
# Fit the PLSRegression object to the training data
pls.fit(X_train, y_train)
# Predict the labels for the test data
y_pred = pls.predict(X_test)
💡注意: 我们选择两个组件是因为从我们的 PCA 分析中我们看到使用两个组件可以分离三个类别。
既然我们已经训练了模型,我们可以评估其性能。我们将使用 scikit-learn 的 准确率分数 和 混淆矩阵 方法来评估模型的性能。
[ ]:
from sklearn.metrics import accuracy_score, confusion_matrix
print("Accuracy: ", accuracy_score(y_test, y_pred.round()))
print("Confusion matrix: \n", confusion_matrix(y_test, y_pred.round()))
Accuracy: 1.0
Confusion matrix:
[[2 0 0]
[0 4 0]
[0 0 6]]
回顾#
咖啡数据集: 通过红外光谱探索咖啡区分的独特世界。该数据集包含来自埃塞俄比亚、巴西和越南的咖啡样本的红外光谱。
导入数据: 使用 chemotools 轻松将咖啡光谱加载到 Pandas DataFrame 中,使数据分析变得轻而易举。
探索、绘图和着色: 深入了解数据集的大小和组成,展示其 60 个样本和 1841 个特征。通过彩色咖啡光谱图可视化数据。
预处理光谱: 深入预处理的世界,chemotools 在此发挥作用。使用标准正态变量(SNV)、导数、范围截取和标准化等技术消除非化学系统变异。
数据建模: 进入机器学习的领域,使用偏最小二乘判别分析(PLS-DA),这是一个强大的分类工具。将标签编码为数值,并将数据分为训练集和测试集。训练模型并评估其性能,获得令人印象深刻的混淆矩阵。
本教程展示了数据科学和化学的美丽,在丰富的光谱数据世界中将咖啡分类的艺术变为现实。