Clasifica cafés con PLS-DA#
💡NOTA: Este documento es un notebook de Jupyter. ¡Puedes descargar el archivo fuente y ejecutarlo en tu entorno Jupyter!
Introducción#
¿Puedes saborear la diferencia entre un café de Etiopía, Brasil o Vietnam?
En este tutorial, usaremos espectroscopía y aprendizaje automático para encontrar el origen de tres cafés diferentes producidos en:
🇪🇹 Ethiopia
🇧🇷 Brazil
🇻🇳 Vietnam
Estos espectros se han recolectado de café preparado usando Espectroscopía Infrarroja Media de Reflectancia Total Atenuada (ATR-MIR).
En esta guía, seguiremos los pasos para crear un modelo de clasificación que pueda diferenciar la huella única del origen de cada café a partir de su firma espectral.
Así que toma tu taza de café favorita, prepárate para adentrarte en el mundo del descubrimiento basado en datos y embarquémonos en este viaje aromático.
💡NOTA: En nuestro conjunto de datos, hemos tostado todo el café bajo las mismas condiciones, pero aquí está el giro: los granos etíopes y brasileños se prepararon como espresso, mientras que el café vietnamita se preparó en una cafetera moka ✨
Objetivo#
En este ejercicio construiremos un modelo PLS-DA para clasificar el origen de muestras de café de tres orígenes diferentes.
Antes de comenzar#
Antes de comenzar, debes asegurarte de tener las siguientes dependencias instaladas:
chemotools
matplotlib
numpy
pandas
scikit-learn
Puedes instalarlas usando
pip install chemotools
pip install matplotlib
pip install numpy
pip install pandas
pip install scikit-learn
Cargando el conjunto de datos de café#
El conjunto de datos de café puede accederse directamente desde el módulo chemotools.datasets, usando la función load_coffee().
[ ]:
from chemotools.datasets import load_coffee
spectra, labels = load_coffee()
La función load_coffee() devuelve dos variables: spectra y labels:
spectra: Unpandas.DataFrameque contiene los espectros de las muestras de café como filas.labels: Unpandas.DataFrameque contiene el origen de cada muestra.
💡NOTA: Si estás interesado en trabajar con
polars.DataFramesimplemente puedes usarload_coffee(set_output="polars").
Explorar, graficar y colorear#
Antes de sumergirnos profundamente en el análisis de datos de café, inspeccionaremos rápidamente los conjuntos de datos. Obtengamos una instantánea de los tamaños de datos e iniciemos nuestro análisis.
[ ]:
print(f"The spectra dataset has {spectra.shape[0]} samples")
print(f"The spectra dataset has {spectra.shape[1]} features")
The spectra dataset has 60 samples
The spectra dataset has 1841 features
El conjunto de datos spectra contiene 60 muestras (filas) y 1841 características (columnas). Cada muestra es un espectro, y cada característica es un número de onda. El conjunto de datos labels contiene el origen de cada muestra. Para analizar el conjunto de datos labels podemos usar el método value_counts() de pandas y hacer un gráfico de barras.
[ ]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 3))
labels.value_counts().plot.bar(color=["Violet", "Salmon", "LightBlue"])
ax.set_ylabel("Number of samples")
ax.set_title("Number of samples per class")
Text(0.5, 1.0, 'Number of samples per class')
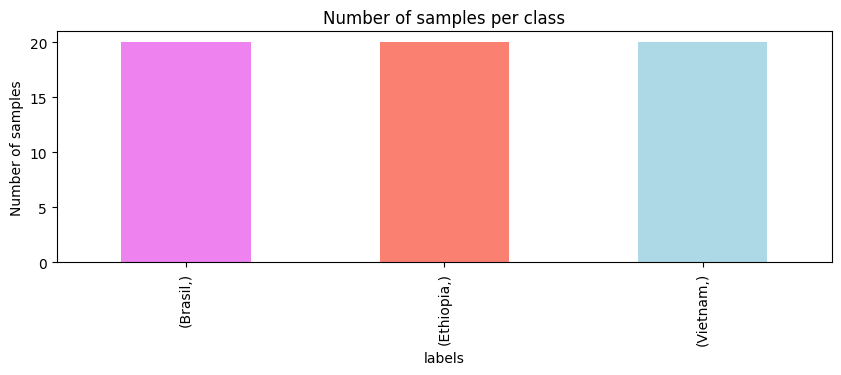
Tenemos un conjunto de datos balanceado con 20 muestras por clase. Ahora que tenemos una mejor comprensión de nuestros datos, comencemos a graficar los espectros. Graficaremos los diferentes espectros y los colorearemos según su origen.
[ ]:
# define a color dictionary for each origin
color_dict = {
"Brasil": "Violet",
"Ethiopia": "Salmon",
"Vietnam": "LightBlue",
}
fig, ax = plt.subplots(figsize=(10, 3))
for i, row in enumerate(spectra.iterrows()):
ax.plot(row[1].values, color=color_dict[labels.iloc[i].values[0]])
ax.set_xlabel("Wavelength (a.u.)")
ax.set_ylabel("Absorbance (a.u.)")
ax.set_title("Coffee spectra")
Text(0.5, 1.0, 'Coffee spectra')
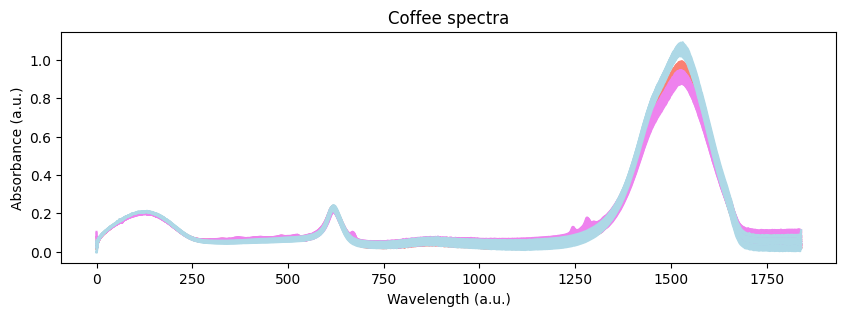
Visualmente, podemos ver que hay algunas diferencias entre los espectros de los tres cafés. Sin embargo, necesitamos profundizar para entender el origen de tales diferencias. Comencemos con un análisis exploratorio. Podemos hacer eso usando un Análisis de Componentes Principales (PCA) para reducir la dimensionalidad de los datos.
Para hacerlo, primero centraremos la media de los datos usando el método de preprocesamiento StandardScaler() de scikit-learn. Luego, usaremos el método PCA(), también de scikit-learn, para reducir la dimensionalidad de los datos a dos componentes principales. Finalmente, graficaremos las puntuaciones y las colorearemos según el origen del café.
💡NOTA: Al usar datos espectroscópicos, no queremos escalar los espectros a varianza unitaria. En su lugar, queremos centrar la media de los datos. Esto es porque la varianza de los espectros está relacionada con la absorbancia del muestra. Si escalamos los datos a varianza unitaria, perderemos la información sobre la absorbancia de la muestra. Podemos centrar la media de los datos usando
StandardScaler()y estableciendo el argumentouse_stdenFalse.
[ ]:
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# standardize the data
spectra_scaled = StandardScaler(with_std=False).fit_transform(spectra)
# make a PCA object
pca = PCA(n_components=2)
# fit and transform the data
spectra_pca = pca.fit(spectra_scaled).transform(spectra_scaled)
# Make a dataframe with the PCA scores
spectra_pca_df = pd.DataFrame(
data=spectra_pca, columns=["PC1", "PC2"], index=spectra.index
)
# Add the labels to the dataframe
spectra_pca_df = pd.concat([spectra_pca_df, labels], axis=1)
# Plot the PCA scores
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(
spectra_pca_df["PC1"],
spectra_pca_df["PC2"],
c=spectra_pca_df["labels"].map(color_dict),
)
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_title("PCA scores")
Text(0.5, 1.0, 'PCA scores')
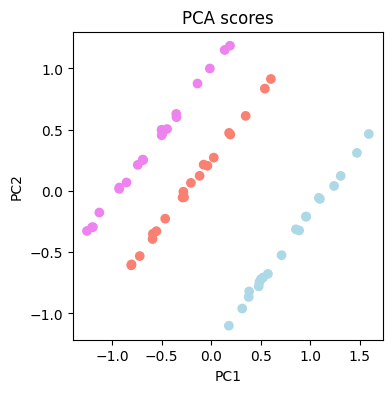
Los resultados muestran que hay algunas diferencias entre los espectros de los tres cafés.
Preprocesando los espectros#
El objetivo del preprocesamiento es eliminar de los espectros variaciones sistemáticas no químicas, como desplazamientos de línea base o efectos de dispersión. Ha habido mucha investigación sobre el preprocesamiento de datos espectroscópicos, y aquí es donde chemotools se vuelve muy útil: aprovechamos el poder de dicha investigación y lo ponemos a tu disposición usando estándares de scikit-learn.
Construiremos los pasos de preprocesamiento en un pipeline usando el método make_pipeline() de sklearn.pipeline. Un pipeline es una secuencia de pasos que se aplican a los datos en un orden dado. En nuestro caso, aplicaremos los siguientes pasos:
Variante normal estándar (SNV) para eliminar efectos de dispersión.
Derivada para eliminar efectos de dispersión tanto aditivos como multiplicativos.
Corte de rango para seleccionar los números de onda más relevantes.
Estandarizar elimina la media del conjunto de datos.
[ ]:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from chemotools.derivative import SavitzkyGolay
from chemotools.feature_selection import RangeCut
from chemotools.scatter import StandardNormalVariate
pipeline = make_pipeline(
StandardNormalVariate(),
SavitzkyGolay(window_size=21, polynomial_order=1),
RangeCut(start=10, end=1350),
StandardScaler(with_std=False),
)
preprocessed_spectra = pipeline.fit_transform(spectra)
💡NOTA: ¡Esto es genial! ¿Ves cómo estamos integrando quimiometría con
scikit-learn?StandardNormalVariate,SavitizkyGolayyRangeCutson todas técnicas de preprocesamiento implementadas enchemotools, mientras queStandardScalerypipelinesson funcionalidades proporcionadas porscikit-learn. Este es el poder dechemotools, está diseñado para trabajar sin problemas conscikit-learn.
Grafiquemos los espectros preprocesados para ver el efecto de los pasos de preprocesamiento.
[ ]:
fig, ax = plt.subplots(figsize=(10, 3))
for i, spectrum in enumerate(preprocessed_spectra):
ax.plot(spectrum, color=color_dict[labels.iloc[i].values[0]])
ax.set_xlabel("Wavelength (a.u.)")
ax.set_ylabel("Absorbance (a.u.)")
ax.set_title("Coffee spectra")
ax.grid()
plt.tight_layout()
plt.show()
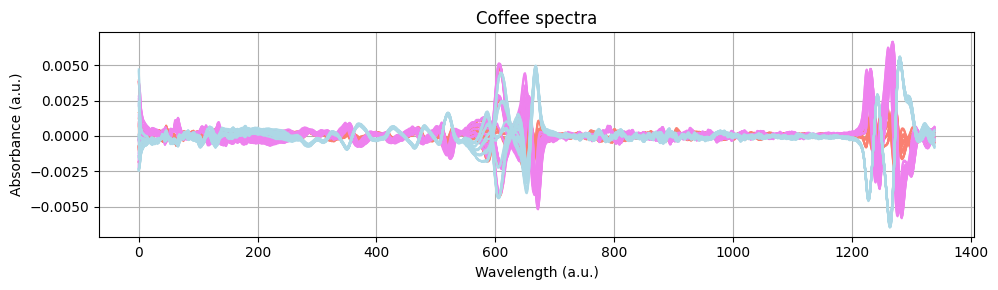
Construyendo un clasificador#
En esta sección, nos sumergiremos en el mundo de la clasificación. ¿Nuestro objetivo? Crear un modelo de clasificación que pueda distinguir los orígenes de nuestros cafés usando sus firmas espectrales.
El Análisis Discriminante de Mínimos Cuadrados Parciales (PLS-DA) es una técnica estadística simple usada para clasificación. PLS-DA modela la relación entre variables de entrada (datos espectrales) y etiquetas de clase (orígenes de café), permitiéndole clasificar nuevas muestras basándose en sus firmas espectrales con alta precisión. Es una herramienta poderosa para reconocimiento de patrones en conjuntos de datos complejos, haciéndola ideal para nuestra clasificación de origen de café.
Antes de comenzar nuestro algoritmo PLS-DA, necesitamos codificar las etiquetas en números. Podemos hacer eso usando el método LabelEncoder() de scikit-learn.
LabelEncoder() asignará un valor categórico a cada una de las etiquetas en nuestro conjunto de datos (0 para Brasil, 1 para Etiopía y 2 para Vietnam).
[ ]:
from sklearn.preprocessing import LabelEncoder
# Make Label Encoder
level_encoder = LabelEncoder()
# Fit the Label Encoder
level_encoder.fit(labels.values.ravel())
# Transform the labels
labels_encoded = level_encoder.transform(labels.values.ravel())
Ahora que nuestras etiquetas de origen de café han sido codificadas en valores numéricos, estamos listos para entrenar nuestro modelo PLS-DA. Sin embargo, antes de comenzar, dividiremos nuestros datos en conjuntos de entrenamiento y prueba usando el método train_test_split() de la biblioteca scikit-learn.
Nuestra estrategia es asignar el 80% de nuestro conjunto de datos para entrenar nuestro modelo, permitiéndole aprender de características distintas de datos espectrales, mientras reservamos el 20% restante para pruebas. Esta división asegura que el rendimiento de nuestro modelo pueda evaluarse en datos no vistos, un paso crucial para evaluar su aplicabilidad en el mundo real y poder predictivo.
[ ]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
preprocessed_spectra, labels_encoded, test_size=0.2, random_state=42
)
💡NOTA: Establecemos el argumento
random_stateen 42 para asegurar la reproducibilidad de los resultados.
Ahora que tenemos nuestros conjuntos de entrenamiento y prueba, podemos comenzar a construir nuestro modelo PLS-DA. Usaremos el método PLSRegression() de scikit-learn. Estableceremos el número de componentes en 2 y el argumento scale en False. Esto es porque ya hemos escalado los datos en el paso de preprocesamiento.
[ ]:
from sklearn.cross_decomposition import PLSRegression
# Make a PLSRegression object
pls = PLSRegression(n_components=2, scale=False)
# Fit the PLSRegression object to the training data
pls.fit(X_train, y_train)
# Predict the labels for the test data
y_pred = pls.predict(X_test)
💡NOTA: Hemos elegido dos componentes porque de nuestro análisis PCA vimos que usando dos componentes podemos separar las tres clases.
Ahora que hemos entrenado nuestro modelo, podemos evaluar su rendimiento. Usaremos la puntuación de precisión y la matriz de confusión de scikit-learn para evaluar el rendimiento del modelo.
[ ]:
from sklearn.metrics import accuracy_score, confusion_matrix
print("Accuracy: ", accuracy_score(y_test, y_pred.round()))
print("Confusion matrix: \n", confusion_matrix(y_test, y_pred.round()))
Accuracy: 1.0
Confusion matrix:
[[2 0 0]
[0 4 0]
[0 0 6]]
Resumen#
El conjunto de datos de café: Explora el mundo único de la diferenciación de café a través de Espectroscopía Infrarroja. Este conjunto de datos contiene espectros IR de muestras de café de Etiopía, Brasil y Vietnam.
Importando los datos: Carga sin esfuerzo los espectros de café en un DataFrame de Pandas usando chemotools, haciendo que el análisis de datos sea muy fácil.
Explorar, graficar y colorear: Obtén información sobre el tamaño y composición del conjunto de datos, mostrando sus 60 muestras y 1841 características. Visualiza los datos con gráficos coloridos de espectros de café.
Preprocesando los espectros: Sumérgete en el mundo del preprocesamiento, donde chemotools entra en juego. Elimina variaciones sistemáticas no químicas usando técnicas como Variante Normal Estándar (SNV), Derivada, Corte de Rango y Estandarización.
Modelando los datos: Entra en el reino del aprendizaje automático con Análisis Discriminante de Mínimos Cuadrados Parciales (PLS-DA), una herramienta poderosa para clasificación. Codifica etiquetas en valores numéricos y divide los datos en conjuntos de entrenamiento y prueba. Entrena el modelo y evalúa su rendimiento, logrando una impresionante matriz de confusión.
Este tutorial muestra la belleza de la ciencia de datos y la química, dando vida al arte de la clasificación de café dentro del rico mundo de los datos espectrales.