PLS-DAでコーヒーを分類#
💡 注意:このドキュメントはJupyterノートブックです。ソースファイルをダウンロードして、Jupyter環境で実行できます!
はじめに#
エチオピア、ブラジル、またはベトナムのコーヒーの味の違いがわかりますか?
このチュートリアルでは、分光法と機械学習を使用して、次の3つの異なる地域で生産されたコーヒーの産地を特定します:
🇪🇹 Ethiopia
🇧🇷 Brazil
🇻🇳 Vietnam
これらのスペクトルは、減衰全反射中赤外分光法(ATR-MIR)を使用して抽出されたコーヒーから収集されました。
このガイドでは、各コーヒーの産地の独特な指紋をスペクトルシグネチャから区別できる分類モデルを作成する手順を説明します。
では、お気に入りのコーヒーマグを手に取り、データ駆動型の発見の世界に飛び込む準備をして、この香り高い旅に出発しましょう。
💡 注意:データセットでは、すべてのコーヒーを同じ条件で焙煎しましたが、ここに注目してください。エチオピアとブラジルの豆はエスプレッソに抽出され、ベトナムのコーヒーはモカポットで抽出されました ✨
目的#
この演習では、3つの異なる産地のコーヒーサンプルの産地を分類するPLS-DAモデルを構築します。
始める前に#
始める前に、以下の依存関係がインストールされていることを確認してください:
chemotools
matplotlib
numpy
pandas
scikit-learn
次のコマンドでインストールできます
pip install chemotools
pip install matplotlib
pip install numpy
pip install pandas
pip install scikit-learn
コーヒーデータセットの読み込み#
コーヒーデータセットは、 chemotools.datasets モジュールから load_coffee() 関数を使用して直接アクセスできます。
[ ]:
from chemotools.datasets import load_coffee
spectra, labels = load_coffee()
The load_coffee() function returns two variables: spectra and labels:
spectra: Apandas.DataFramecontaining the spectra of the coffee samples as rows.labels: Apandas.DataFramecontaining the origin of each sample.
💡 注意:
polars.DataFrameを使用したい場合は、load_coffee(set_output="polars")を使用するだけです。
探索、プロット、色付け#
コーヒーデータ分析に深く入る前に、データセットを簡単に検査します。データサイズのスナップショットを取得して、分析を開始しましょう。
[ ]:
print(f"The spectra dataset has {spectra.shape[0]} samples")
print(f"The spectra dataset has {spectra.shape[1]} features")
The spectra dataset has 60 samples
The spectra dataset has 1841 features
The spectra dataset contains 60 samples (rows) and 1841 features (columns). Each sample is a spectrum, and each feature is a wavenumber. The labels dataset contains the origin of each sample. To analyze the labels dataset we can use the value_counts() method from pandas and make a bar plot.
[ ]:
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 3))
labels.value_counts().plot.bar(color=["Violet", "Salmon", "LightBlue"])
ax.set_ylabel("Number of samples")
ax.set_title("Number of samples per class")
Text(0.5, 1.0, 'Number of samples per class')
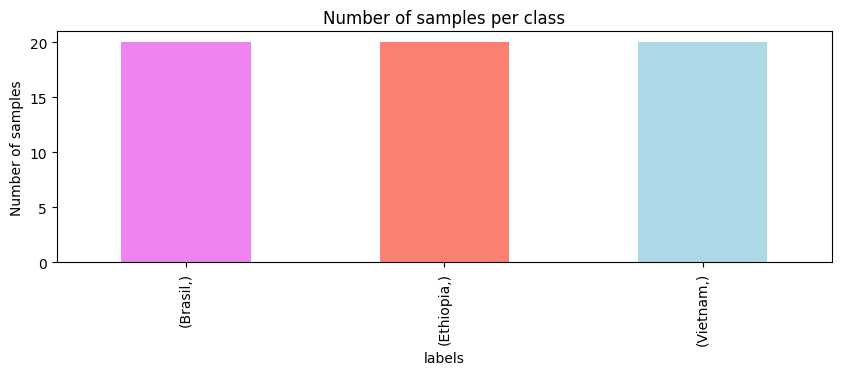
クラスごとに20サンプルを持つバランスの取れたデータセットがあります。データの理解が深まったので、スペクトルのプロットを始めましょう。異なるスペクトルをプロットし、産地別に色分けします。
[ ]:
# define a color dictionary for each origin
color_dict = {
"Brasil": "Violet",
"Ethiopia": "Salmon",
"Vietnam": "LightBlue",
}
fig, ax = plt.subplots(figsize=(10, 3))
for i, row in enumerate(spectra.iterrows()):
ax.plot(row[1].values, color=color_dict[labels.iloc[i].values[0]])
ax.set_xlabel("Wavelength (a.u.)")
ax.set_ylabel("Absorbance (a.u.)")
ax.set_title("Coffee spectra")
Text(0.5, 1.0, 'Coffee spectra')
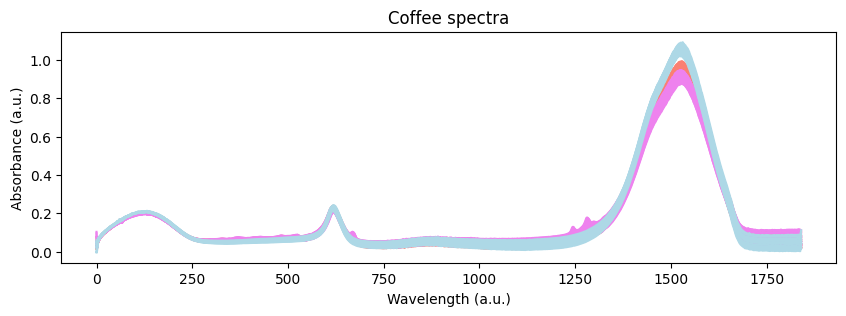
視覚的に、3つのコーヒーのスペクトル間にいくつかの違いがあることがわかります。ただし、このような違いの原因を理解するには、さらに深く掘り下げる必要があります。探索的分析から始めましょう。主成分分析(PCA)を使用してデータの次元を削減することでこれを行うことができます。
そのために、まず scikit-learn の StandardScaler() 前処理メソッドを使用してデータを平均中心化します。次に、同じく scikit-learn の PCA() メソッドを使用して、データの次元を2つの主成分に削減します。最後に、スコアをプロットし、コーヒーの産地に従って色分けします。
💡 注意:分光データを使用する場合、スペクトルを単位分散にスケーリングしたくありません。代わりに、データを平均中心化したいと考えます。これは、スペクトルの分散がサンプルの吸光度に関連しているためです。データを単位分散にスケーリングすると、サンプルの吸光度に関する情報が失われます。
StandardScaler()を使用し、use_std引数をFalseに設定することで、データを平均中心化できます。
[ ]:
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# standardize the data
spectra_scaled = StandardScaler(with_std=False).fit_transform(spectra)
# make a PCA object
pca = PCA(n_components=2)
# fit and transform the data
spectra_pca = pca.fit(spectra_scaled).transform(spectra_scaled)
# Make a dataframe with the PCA scores
spectra_pca_df = pd.DataFrame(
data=spectra_pca, columns=["PC1", "PC2"], index=spectra.index
)
# Add the labels to the dataframe
spectra_pca_df = pd.concat([spectra_pca_df, labels], axis=1)
# Plot the PCA scores
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(
spectra_pca_df["PC1"],
spectra_pca_df["PC2"],
c=spectra_pca_df["labels"].map(color_dict),
)
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_title("PCA scores")
Text(0.5, 1.0, 'PCA scores')
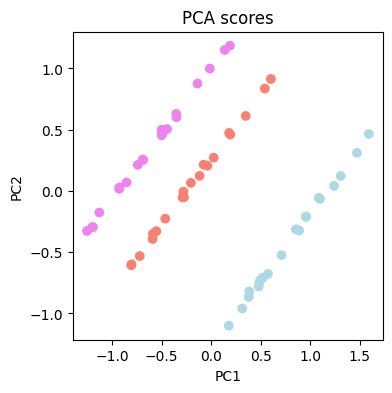
結果は、3つのコーヒーのスペクトル間にいくつかの違いがあることを示しています。
スペクトルの前処理#
前処理の目的は、ベースラインシフトや散乱効果などの非化学的な系統的変動をスペクトルから除去することです。分光データの前処理については多くの研究が行われており、ここで chemotools が非常に便利です。そのような研究の力を活用し、 scikit-learn 標準を使用して利用できるようにしています。
We will build the preprocessing steps in a pipeline using the make_pipeline() method from sklearn.pipeline. A pipeline is a sequence of steps that are applied to the data in a given order. In our case, we will apply the following steps:
標準正規変量(SNV) で散乱効果を除去します。
微分 で加算的および乗算的な散乱効果の両方を除去します。
範囲カット で最も関連性の高い波数を選択します。
標準化 でデータセットから平均を除去します。
[ ]:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from chemotools.derivative import SavitzkyGolay
from chemotools.feature_selection import RangeCut
from chemotools.scatter import StandardNormalVariate
pipeline = make_pipeline(
StandardNormalVariate(),
SavitzkyGolay(window_size=21, polynomial_order=1),
RangeCut(start=10, end=1350),
StandardScaler(with_std=False),
)
preprocessed_spectra = pipeline.fit_transform(spectra)
💡 注意:これは素晴らしいです!ケモメトリクスを
scikit-learnとどのように統合しているかご覧ください。StandardNormalVariate、SavitizkyGolay、RangeCutはすべてchemotoolsに実装された前処理技術であり、StandardScalerとpipelinesはscikit-learnによって提供される機能です。これがchemotoolsの力であり、scikit-learnとシームレスに動作するように設計されています。
前処理されたスペクトルをプロットして、前処理ステップの効果を見てみましょう。
[ ]:
fig, ax = plt.subplots(figsize=(10, 3))
for i, spectrum in enumerate(preprocessed_spectra):
ax.plot(spectrum, color=color_dict[labels.iloc[i].values[0]])
ax.set_xlabel("Wavelength (a.u.)")
ax.set_ylabel("Absorbance (a.u.)")
ax.set_title("Coffee spectra")
ax.grid()
plt.tight_layout()
plt.show()
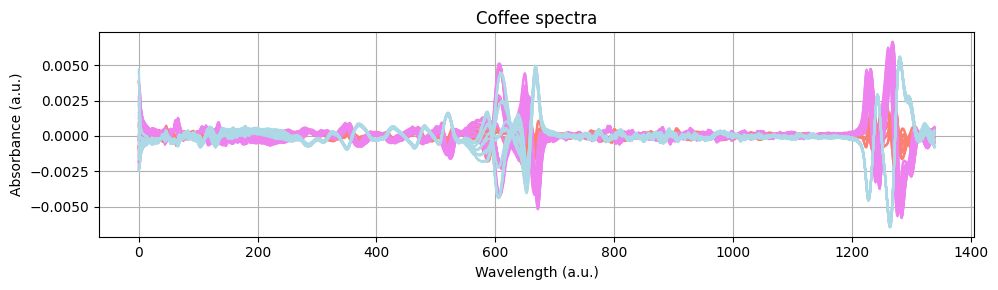
分類器の構築#
このセクションでは、分類の世界に飛び込みます。目標は?スペクトルシグネチャを使用してコーヒーの産地を区別できる分類モデルを作成することです。
部分最小二乗判別分析(PLS-DA)は、分類に使用されるシンプルな統計手法です。PLS-DAは、入力変数(スペクトルデータ)とクラスラベル(コーヒーの産地)の間の関係をモデル化し、スペクトルシグネチャに基づいて新しいサンプルを高精度で分類できます。複雑なデータセットでのパターン認識のための強力なツールであり、コーヒーの産地分類に最適です。
PLS-DAアルゴリズムを開始する前に、ラベルを数値にエンコードする必要があります。これは scikit-learn の LabelEncoder() メソッドを使用して実行できます。
LabelEncoder() は、データセット内の各ラベルにカテゴリ値を割り当てます(ブラジルは0、エチオピアは1、ベトナムは2)。
[ ]:
from sklearn.preprocessing import LabelEncoder
# Make Label Encoder
level_encoder = LabelEncoder()
# Fit the Label Encoder
level_encoder.fit(labels.values.ravel())
# Transform the labels
labels_encoded = level_encoder.transform(labels.values.ravel())
コーヒーの産地ラベルが数値にエンコードされたので、PLS-DAモデルを訓練する準備ができました。ただし、開始する前に、 scikit-learn ライブラリの train_test_split() メソッドを使用して、データを訓練セットとテストセットに分割します。
戦略は、データセットの80%をモデルの訓練に割り当て、スペクトルデータの特徴的な特性から学習させることです。残りの20%はテスト用に確保します。この分割により、モデルのパフォーマンスを未見のデータで評価できます。これは、実世界での適用可能性と予測力を評価するための重要なステップです。
[ ]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
preprocessed_spectra, labels_encoded, test_size=0.2, random_state=42
)
💡 注意:
random_state引数を42に設定して、結果の再現性を確保しています。
訓練セットとテストセットを用意したので、PLS-DAモデルの構築を開始できます。 scikit-learn の PLSRegression() メソッドを使用します。コンポーネント数を2に設定し、 scale 引数を False に設定します。これは、前処理ステップでデータをすでにスケーリングしているためです。
[ ]:
from sklearn.cross_decomposition import PLSRegression
# Make a PLSRegression object
pls = PLSRegression(n_components=2, scale=False)
# Fit the PLSRegression object to the training data
pls.fit(X_train, y_train)
# Predict the labels for the test data
y_pred = pls.predict(X_test)
💡 注意:PCA分析から、2つのコンポーネントを使用すると3つのクラスを分離できることがわかったため、2つのコンポーネントを選択しました。
モデルを訓練したので、そのパフォーマンスを評価できます。モデルのパフォーマンスを評価するために、 scikit-learn の accuracy score と confusion matrix メソッドを使用します。
[ ]:
from sklearn.metrics import accuracy_score, confusion_matrix
print("Accuracy: ", accuracy_score(y_test, y_pred.round()))
print("Confusion matrix: \n", confusion_matrix(y_test, y_pred.round()))
Accuracy: 1.0
Confusion matrix:
[[2 0 0]
[0 4 0]
[0 0 6]]
まとめ#
コーヒーデータセット:赤外分光法によるコーヒーの差別化のユニークな世界を探求します。このデータセットには、エチオピア、ブラジル、ベトナムのコーヒーサンプルのIRスペクトルが含まれています。
データのインポート:
chemotoolsを使用してコーヒースペクトルをPandas DataFrameに簡単にロードし、データ分析を容易にします。探索、プロット、色付け:データセットのサイズと構成についての洞察を得て、60サンプルと1841特徴を示します。カラフルなコーヒースペクトルプロットでデータを視覚化します。
スペクトルの前処理:
chemotoolsが活躍する前処理の世界に飛び込みます。標準正規変量(SNV)、微分、範囲カット、標準化などの技術を使用して、非化学的な系統的変動を排除します。データのモデリング:部分最小二乗判別分析(PLS-DA)という分類のための強力なツールを使用して、機械学習の領域に入ります。ラベルを数値にエンコードし、データを訓練セットとテストセットに分割します。モデルを訓練してパフォーマンスを評価し、印象的な混同行列を達成します。
このチュートリアルは、データサイエンスと化学の美しさを示し、スペクトルデータの豊かな世界でコーヒー分類の芸術を生き生きとさせます。